
Raising the Standards of Modelling
This feature considers the “bigger picture” for modelling: what constitutes a “Best Practice” model. By Liam Bastick, director with SumProduct Pty Ltd.
Query
In a previous article you discussed the merits of using styles, but can you give me any tips for model construction in general?
Advice
Spreadsheeting is often seen as a core skill for finance professionals, many of whom are reasonably conversant with Excel. However, many would-be modellers frequently forget that the key end users of a spreadsheet model (i.e. the decision makers) are not necessarily sophisticated Excel users and often only see the final output on a printed page, e.g. as an appendix to a Word document or as part of a set of PowerPoint slides.
With this borne in mind, it becomes easier to understand why there have been numerous high profile examples of material spreadsheet errors. I am not saying that well-structured models will ensure no mistakes, but in theory it should reduce both the number and the magnitude of these errors.
Modellers should strive to build “Best Practice” models. Here, I want to avoid the semantics of what constitutes ‘best” in “Best Practice”. Instead, I would rather we consider the term as a proper noun to reflect the idea that a good model has four key attributes:
- Transparency;
- Consistency;
- Flexibility; and
- Robustness.
Looking at these four attributes in turn can help model developers decide how best to design financial models.
Transparency
As stated above, many modellers often forget that key decision makers base their choices on printed materials: consequently, models must be clear, concise, and fit for the purpose intended.
Most Excel users are familiar with keeping inputs / assumptions away from calculations away from outputs. However, this concept can be extended: it can make sense to keep different areas of a model separate, e.g. revenue assumptions on a different worksheet from cost(s) of goods sold assumptions, and capital expenditure assumptions on a third sheet, and so on. This makes it easier to re-use worksheets and ringfence data. Keeping base case data away from sensitivity data is also important, as many modelling mistakes have been made from users changing the wrong, yet similar, inputs.
Aside from trying to keep formulae as simple as possible, it makes sense to consider the logical flow of a model at the outset too. Indeed, including a simple flowchart within an Excel workbook can be invaluable: as the saying goes, a picture is worth a thousand words, and can actually help to plan the structure and order of the spreadsheet build.
Similarly, a Navigation Page constructed with hyperlinks helps users and developers alike navigate through larger Excel models:
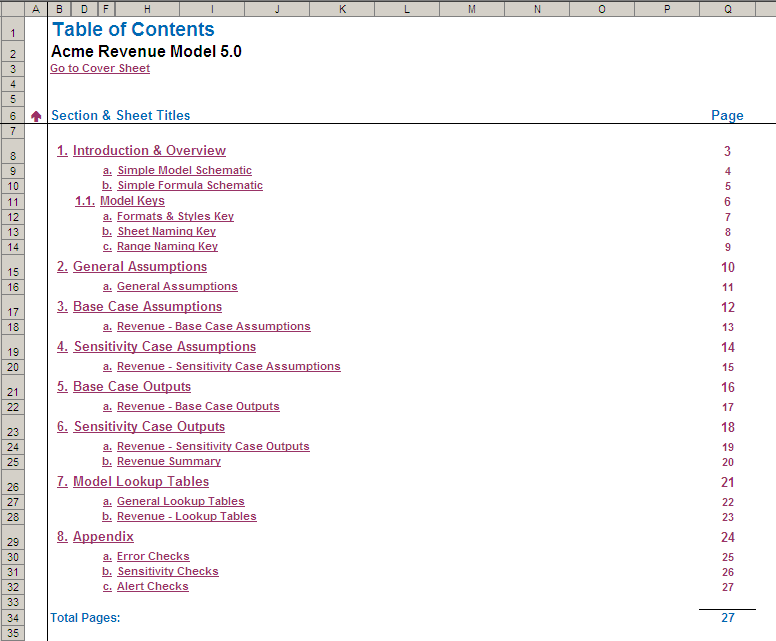
Consistency
Models constructed consistently are easier to understand as users become familiar with both their purpose and content. This will in turn give users more comfort about model integrity and make it easier to add / remove categories, numbers of periods, scenarios etc.
Consistent formatting and use of styles cannot be over-emphasised. Humans take in much information on a non-verbal basis. Consider the following ‘Print’ dialog box:
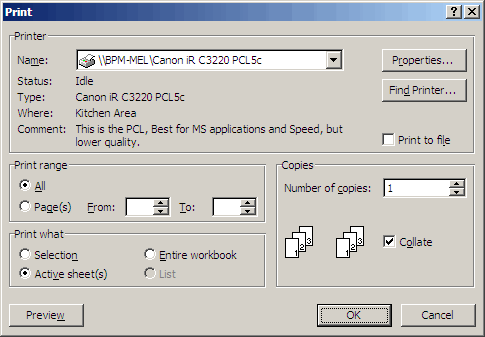
We may not realise it but we have all been indoctrinated by Microsoft. Whilst the above dialog box appears quite flexible, we know the only things we are able to change are the objects in white (for example, I know I cannot print out a list from the above dialog box since the selection has been greyed out).
Those of you familiar with the models I have attached to many of these articles may now realise I exploit this mindset: the worksheets in my workbooks that contain objects or cells that may be modified by the user are typically grey in background, with the objects / cells themselves white – we are all Pavlov’s dogs!
There are other key elements of a workbook that should be consistent. These include:
- Formulae should be copied uniformly across ranges, to make it easy to add / remove periods or categories as necessary;
- Sheet titles and hyperlinks should be consistently positioned to aid navigation and provide details about the content and purpose of the particular worksheet;
- For forecast spreadsheets incorporating dates, the dates should be consistently positioned (i.e. first period should always be in one particular column), the number of periods should be consistent where possible and the periodicity should be uniform (the model should endeavour to show all sheets monthly or quarterly, etc.). If periodicities must change, they should be in clearly delineated sections of the model.
This should reduce referencing errors, increase model integrity and enhance workbook structure.
Flexibility
One benefit of modelling in a spreadsheet package such as Excel is to be able to change various assumptions and see how these adjustments affect various outputs.
Therefore, when building a model, the user should consider what inputs should be variable and how they should be able to vary. This may force the model builder to consider how assumptions should be entered.
The most common method of data entry in practice is simply typing data into worksheet cells, but this may allow a model’s inputs to vary outside of scoped parameters. For example, if I have a cell seeking ‘Volumes’, without using data validation I could enter ‘3’, ‘-22.8’ or ‘dog’ in that cell. Negative volumes are nonsensical and being able to enter text may cause formula errors throughout the model. Therefore, the user may wish to consider other methods of entry including using drop down boxes, option buttons, check boxes and so on.
The aim is to have a model provide sufficient flexibility without going overboard.
Robustness
Models should be materially free from error, mathematically accurate and readily auditable. Key output sheets should ensure that error messages such as #DIV/0!, #VALUE!, #REF! etc. cannot occur (ideally, these error messages should not occur anywhere).
When building, it is often worth keeping in mind hidden assumptions in formula. For example, a simple gross margin calculation may calculate profit divided by sales. However, if sales are non-existent or missing, this calculation would give #DIV/0! The user therefore has two options:
- Use an IF statement to check that sales are not zero (proactive test); or
- Construct an error check to flag if sales are zero (reactive test, not recommended in this instance).
However, checks are useful in many situations, and essentially each will fit into one of three categories:
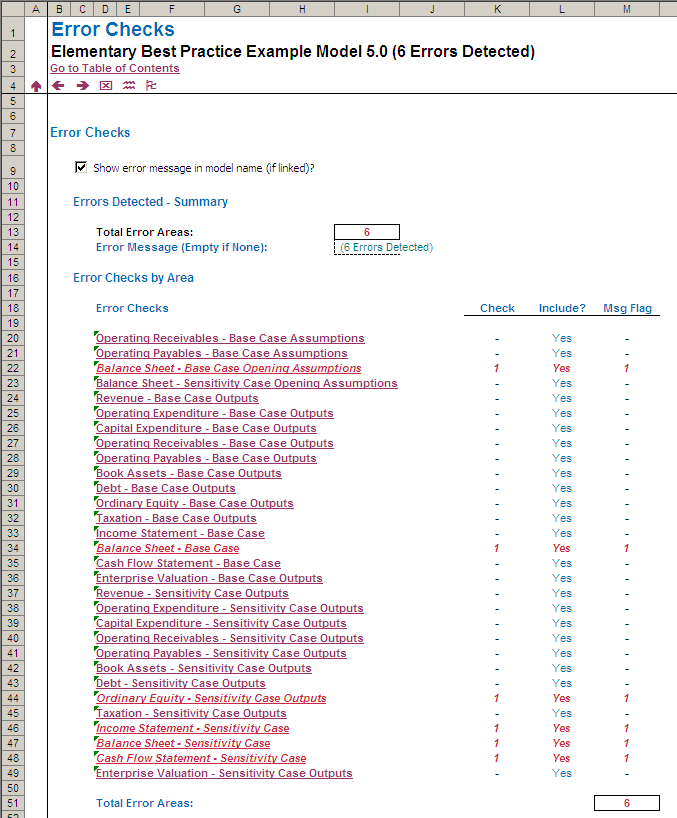
- Error checks – the model contains flawed logic or prima facie errors, e.g. balance sheet does not balance, cash in cashflow statement does not reconcile with the balance sheet, or the model contains #DIV/0! errors etc;
- Sensitivity checks – the model’s outputs are being derived from inputs that are not deemed to be part of the base case. This can prevent erroneous decisions being made; and
- Alert checks – everything else! This flags points of interest to users and / or developers issues that may need to be reviewed: e.g. revenues are negative, debt covenants have been breached, etc.
Incorporating dedicated worksheets into the model that summarise these checks will enhance robustness and give users more confidence that the model is working / calculating as intended.
Further Reading
The above merely scratches the surface of what constitutes a “Best Practice” model. If you would like to read more, theer are various bodies of work available in cyberspace including the ‘Best Practice Modelling Standards’ from The Spreadsheet Standards Review Board (SSRB).
These Standards have been collated over the last seven years by talking to many experienced modellers worldwide endeavouring to reach consensus about the do’s and don’t’s of model construction.
If you have a query for this section, please feel free to drop Liam a line at liam.bastick@sumproduct.com or visit the website www.sumproduct.com