Recent Text and Array Functions: an Update
22 June 2022
Microsoft has elected to “…enhance the signatures of the text functions…” as follows. The software giant has:
- added [match end] to TEXTBEFORE and TEXTAFTER. This will allow you to request a match against the end of the text
- renamed [ignore case] to [match mode] for TEXTBEFORE and TEXTAFTER
- added [match mode] to TEXTSPLIT to be more consistent with TEXTBEFORE and TEXTAFTER
- added [if not found] to TEXTBEFORE and TEXTAFTER. This expression is returned instead of #N/A when there is no delimiter match.
The updated text functions will become available to Beta channel users starting with build 15316.20000. The function documentation will be updated to reflect these changes in the coming weeks. Please note that you will need to update your TEXTSPLIT functions if you used the [pad with] argument, as this argument has moved from the fifth to the sixth argument. All of the other changes are backwards compatible.
Let’s take a look at the three functions that have been updated.
The TEXTBEFORE function
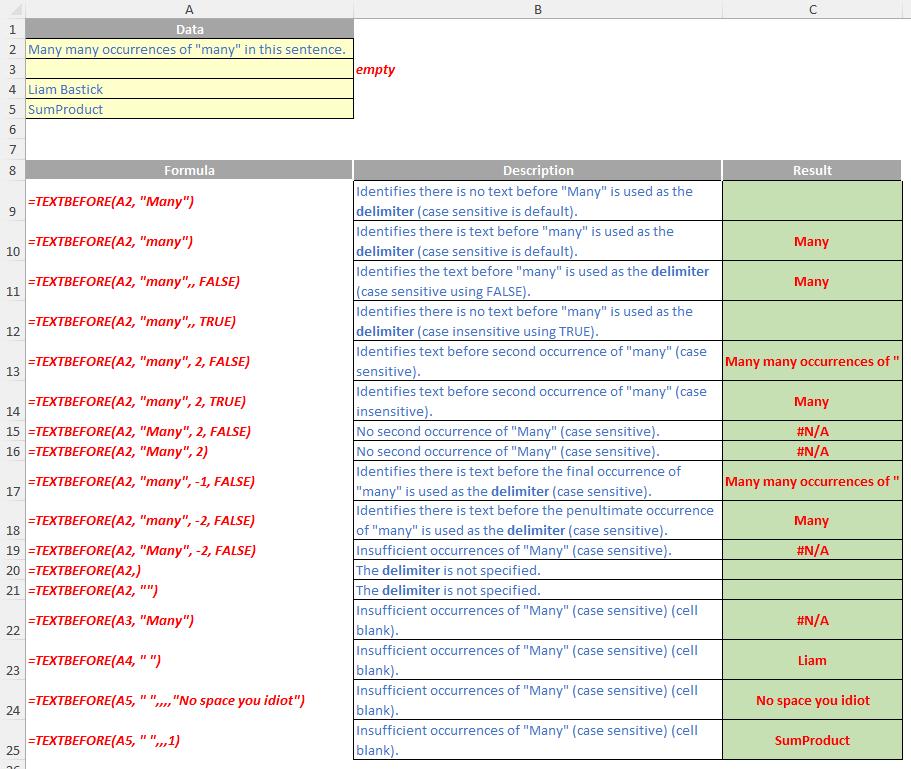
The TEXTBEFORE function returns the string of text that occurs before a given substring (i.e. a character or set of characters) in that string. It is the opposite of the TEXTAFTER function. TEXTBEFORE has the following syntax:
TEXTBEFORE(text, delimiter, [instance number], [match mode], [match end], [if not found])
The TEXTBEFORE function has the following arguments:
- text: this is required and represents the text string you are searching within. Wildcard characters are not allowed
- delimiter: this is also required and represents the text in the text string that marks the point before which you wish to extract
- instance number: this is the first optional argument and denotes the nth instance of the delimiter before which you wish to extract. By default, this is equal to one [1]. If a negative number is used here, the function starts searching for the delimiter from the end rather than the beginning
- match mode: this is the second optional argument, and determines whether the text search is case-sensitive. The default is case-sensitive. If used, you should enter one of the following two [2] values:
o 0: case sensitive
o 1: case insensitive
- match end: also optional, this treats the end of the text as a delimiter. By default this is viewed as an exact match. If used, you should enter one of the following two [2] values:
o 0: do not match the delimiter against the end of the text
o 1: match the delimiter against the end of the text
- if not found: this too is an optional argument and provides the value should no match be found. If not used and no match is found, #N/A will be returned.
It should be further noted that:
- when searching with an empty delimiter value, TEXTBEFORE matches immediately. It returns empty text when searching from the front (if instance number is positive) and the entire text when searching from the end (if instance number is negative)
- Excel returns an #VALUE! error if the instance number is zero (the default is one) or if the instance number is greater than the length of the text
- Excel returns an #N/A error if the delimiter does not occur within the text
- Excel returns an #N/A error if the instance number is greater than the number of occurrences of the delimiter within the text.
Please see the examples below:
The TEXTAFTER function
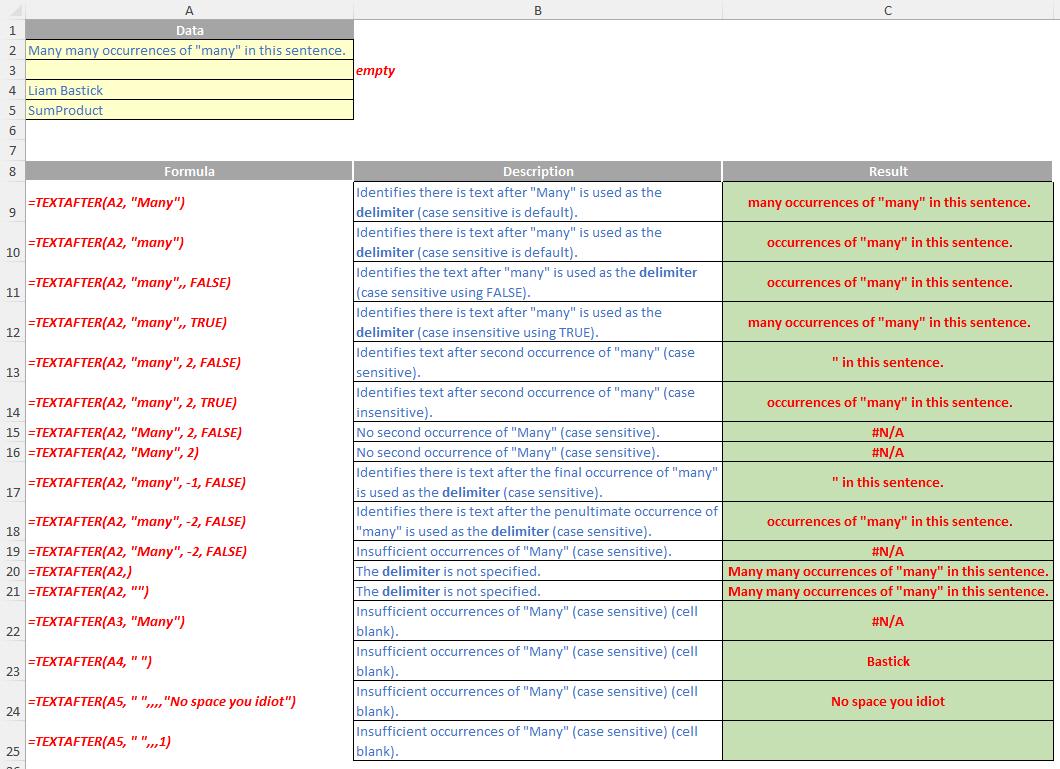
The TEXTAFTER function returns the string of text that occurs after a given substring (i.e. a character or set of characters) in that string. It is the opposite of the TEXTBEFORE function. TEXTAFTER has the following syntax:
TEXTAFTER(text, delimiter, [instance number], [match mode], [match end], [if not found])
The TEXTAFTER function has the following arguments:
- text: this is required and represents the text string you are searching within. Wildcard characters are not allowed
- delimiter: this is also required and represents the text in the text string that marks the point after which you wish to extract
- instance number: this is the first optional argument and denotes the nth instance of the delimiter after which you wish to extract. By default, this is equal to one [1]. If a negative number is used here, the function starts searching for the delimiter from the end rather than the beginning
- match mode: this is the second optional argument, and determines whether the text search is case-sensitive. The default is case-sensitive. If used, you should enter one of the following two [2] values:
o 0: case sensitive
o 1: case insensitive
- match end: also optional, this treats the end of the text as a delimiter. By default this is viewed as an exact match. If used, you should enter one of the following two [2] values:
o 0: do not match the delimiter against the end of the text
o 1: match the delimiter against the end of the text
- if not found: this too is an optional argument and provides the value should no match be found. If not used and no match is found, #N/A will be returned.
It should be further noted that:
- when searching with an empty delimiter value, TEXTAFTER matches immediately. It returns the entire text when searching from the front (if instance number is positive) and empty text when searching from the end (if instance number is negative)
- Excel returns an #VALUE! error if the instance number is zero (the default is one) or if the instance number is greater than the length of the text
- Excel returns an #N/A error if the delimiter does not occur within the text
- Excel returns an #N/A error if the instance number is greater than the number of occurrences of the delimiter within the text.
Please see relevant examples below:
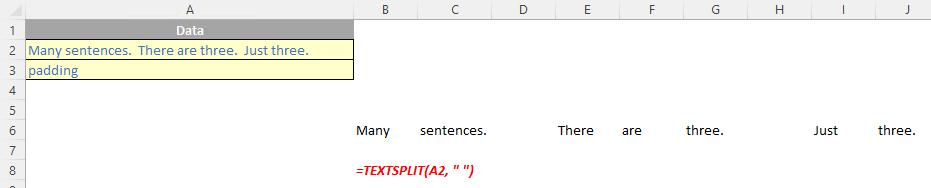
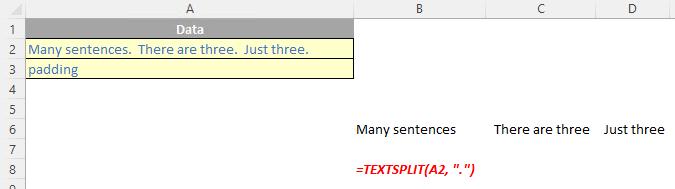
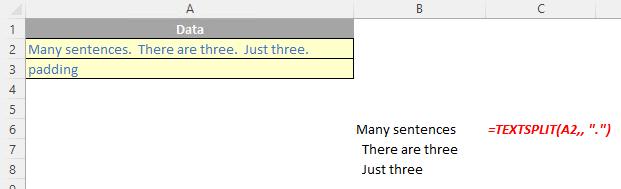
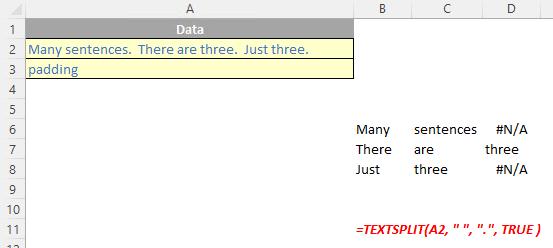
The TEXTSPLIT function
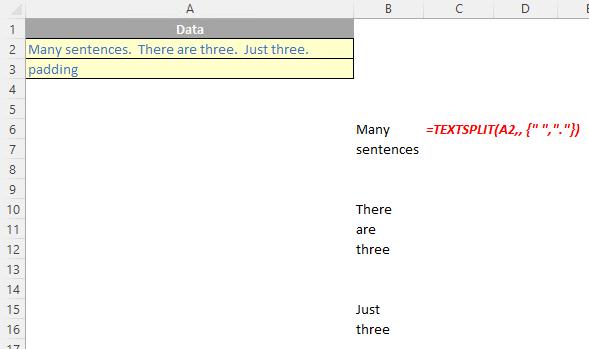
The TEXTSPLIT function is intended to work like the Text to Columns button on the Data tab of the Ribbon, almost like the “inverse” of the TEXTJOIN function. It allows you to split a given text across rows or down columns. TEXTSPLIT has the following syntax:
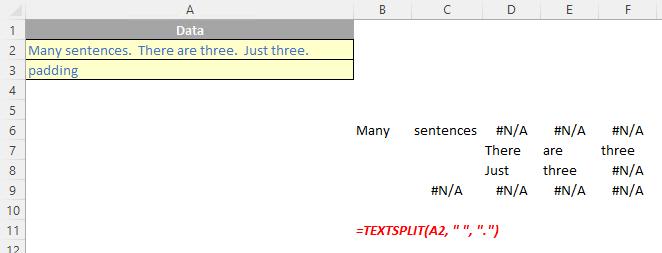
TEXTSPLIT(text, [column delimiter], [row delimiter], [ignore empty], [match mode], [pad with])
The TEXTSPLIT function has the following arguments:
- text: this is required and represents the text string you wish to split
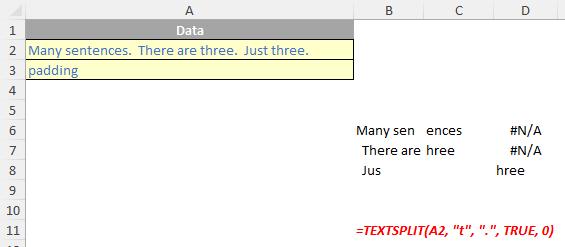
- column delimiter: this is optional and denotes one or more characters that specify where to spill the text across columns
- row delimiter: this is optional and denotes one or more characters that specify where to spill the text down rows
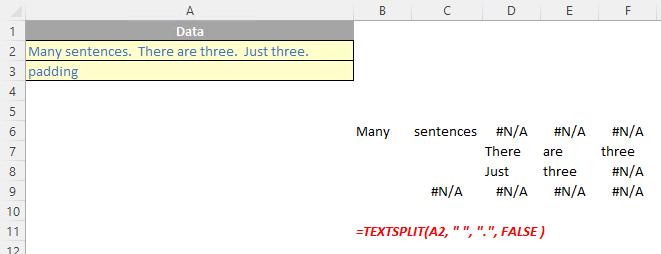
- ignore empty: another optional argument, you should specify TRUE to create an empty cell when two delimiters are used. This argument defaults to FALSE, which means don't create an empty cell
- match mode: this is the second optional argument, and determines whether the text search is case-sensitive. The default is case-sensitive. If used, you should enter one of the following two [2] values:
o 0: case sensitive
o 1: case insensitive
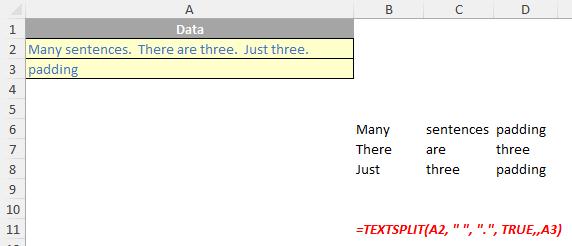
- pad with: not to be confused with Pad Thai, this final optional argument “pads” the resulting text range where cells would otherwise be blank. The default is N/A.
Please note that you will need to update any TEXTSPLIT functions previously written if you used the pad with argument, as this argument has moved from the fifth to the sixth argument.
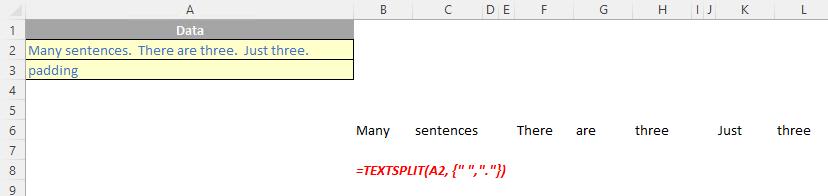
If there is more than one delimiter (row or column), then an array constant must be used. For example, to split by both a comma (,) and a period (full stop, .), use =TEXTSPLIT(text, {",", "."}).
Just for a change, some more examples: