
Power Query: PDF Pandemonium – Part 1
15 September 2021
Welcome to our Power Query blog. This week, I look at extracting data from a PDF file.
The tent business is doing well, and the UK division has plans to expand the workforce. I have a PDF file, with data for 10 stores. The information could change for any of those stores, and the way that the information is given is similar to the following:
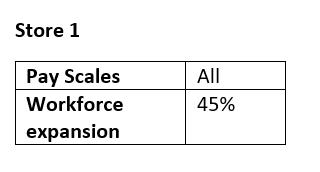
or maybe like this:

or even like this:
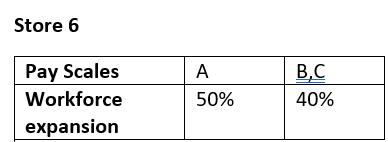
My goal is to get all this information into one table.
Somewhere in the middle of my data, I have some text, which although very useful to the company, is no help to me.
‘There may be plans to build a further store which would require a new workforce, but planning permission has not been granted. Also, we would like to see the Projected Pay increases on the report.’
This could be added to, reduced or removed.
However, there is also another table, which I do wish to extract, although not in its current form (that would be too easy!).

This means I don’t know how many pages are in the PDF. I would normally expect to see data for 10 stores, and they are all split into three [3] pay scales. This week, I will be extracting the data.
I start in an empty Excel Workbook, in the ‘Get and Transform’ section of the Data tab, where I will use ‘Get Data’ and then ‘From File’, where I may choose ‘From PDF’.
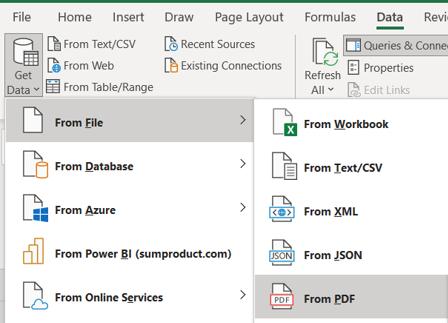
This allows me to browse to choose the PDF I want to extract. I am then presented with the following dialog:
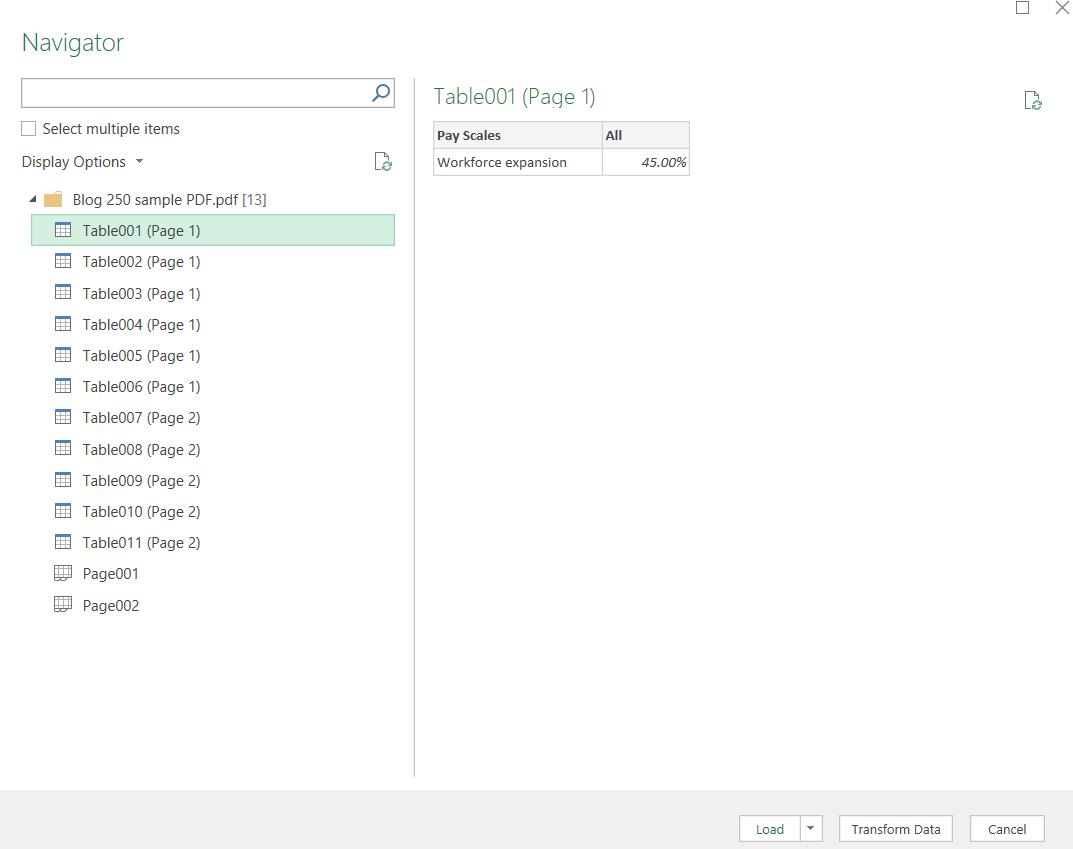
This is my first decision: I need to know whether to pick tables or pages. The best way to decide this is to look at what is in them by selecting one of them for preview.
I skip to the end of the content list, and look at one of the tables:
Not much in there, do I really need to get every table? There’s not even a way to link this to a store.
I look at what is in the pages:
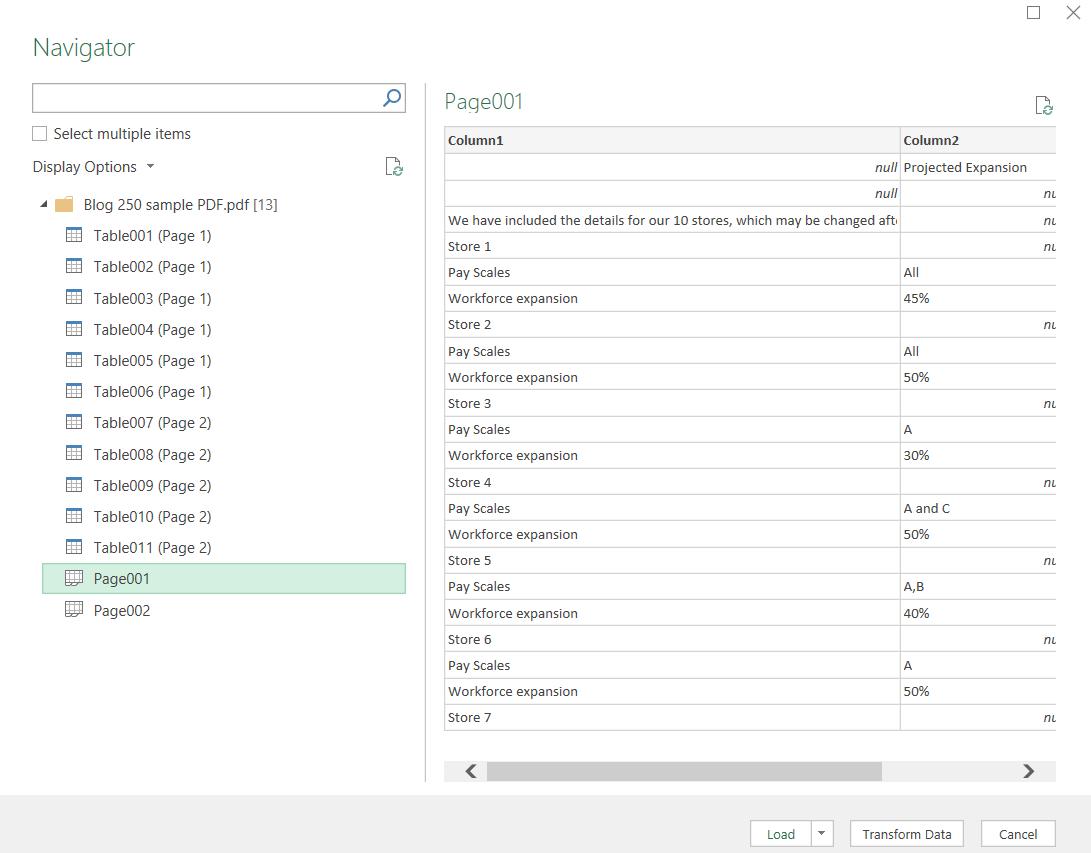
Definitely more data, and stores are also included. I can select multiple items, but do I select all the pages? What if there are more next time?
There is an easier way. If I select the folder icon, I have other options…
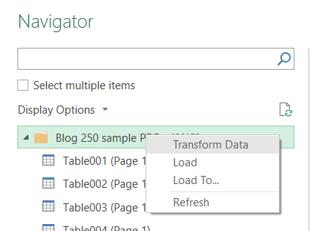
I can ‘Transform Data’. This means all the data in the folder will be loaded into Power Query. This is exactly what I want.
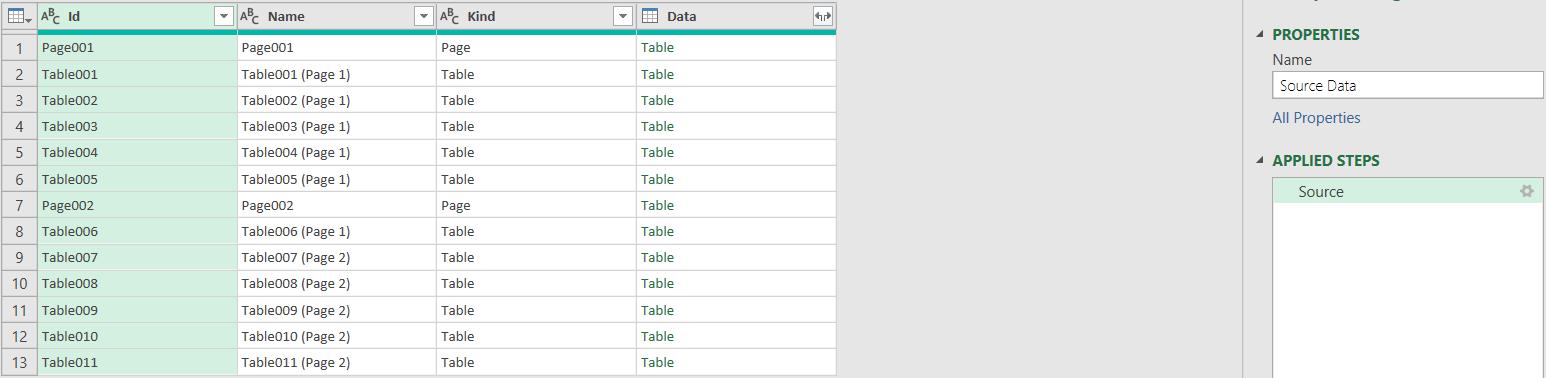
Here it is. All the tables, and all the pages. The M code for this is:
= Pdf.Tables(File.Contents("FileLocation\Blog 250 Sample PDF.pdf"), [Implementation="1.3"])
FileLocation is where I have stored the file on my PC, and ‘Blog 250 Sample PDF’ is the name of the file.
This is using the M function Pdf.Tables():
Pdf.Tables(pdf as binary, optional options as nullable record) as table
This returns any tables found in pdf. An optional record parameter, options, may be provided to specify additional properties. The record can contain the following fields:
- Implementation: the version of the algorithm to use when identifying tables. Old versions are available only for backwards compatibility, to prevent old queries from being broken by algorithm updates. The newest version should always give the best results. Valid values are "1.3", "1.2", "1.1", or null
- StartPage: specifies the first page in the range of pages to examine; the default value is one [1]
- EndPage: specifies the last page in the range of pages to examine. The default value here is the last page of the document
- MultiPageTables: controls whether similar tables on consecutive pages will be automatically combined into a single table. Here, the default value is true
- EnforceBorderLines: controls whether border lines are always enforced as cell boundaries (when true), or simply used as one hint among many for determining cell boundaries (when false). The default value here is false.
This explains where [Implementation="1.3"] comes from. It is the algorithm version, and appears to be the latest version, which is reassuring.
So back to my extracted data; I know I want the page data, so I can filter the Id column to get everything beginning with ‘Page’:
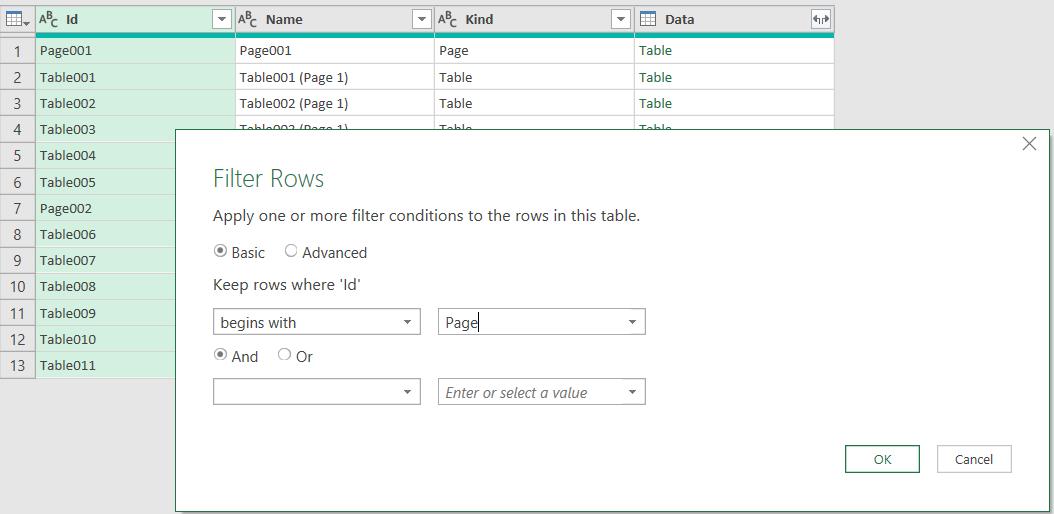
This gives me just the pages. I only need the Data column now, so I select it and opt to ‘Remove Other Columns’.
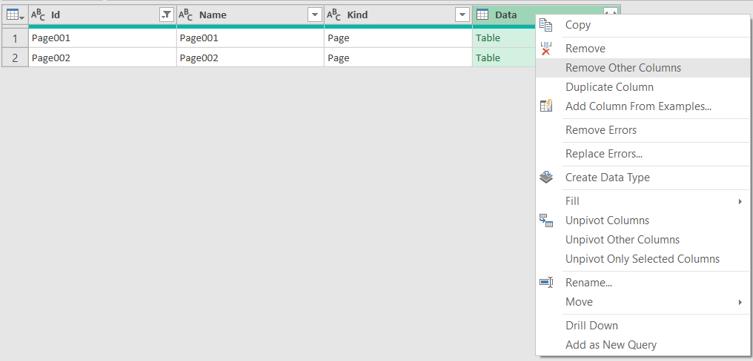
I can then expand the data, which extracts to columns 1 to 7:

I am ready to start transforming my data, which is where I will begin next time.
Come back next time for more ways to use Power Query!