
Power Query: Flat with a View
7 April 2021
Welcome to our Power Query blog. This week, I look at how to improve the memory used when loading my flat file query to Power BI Desktop.
I have a query which extracts data from flat files. Last week, I looked at how I could improve the memory used while processing my query, and I added Table.Buffer() and List.Buffer() steps.
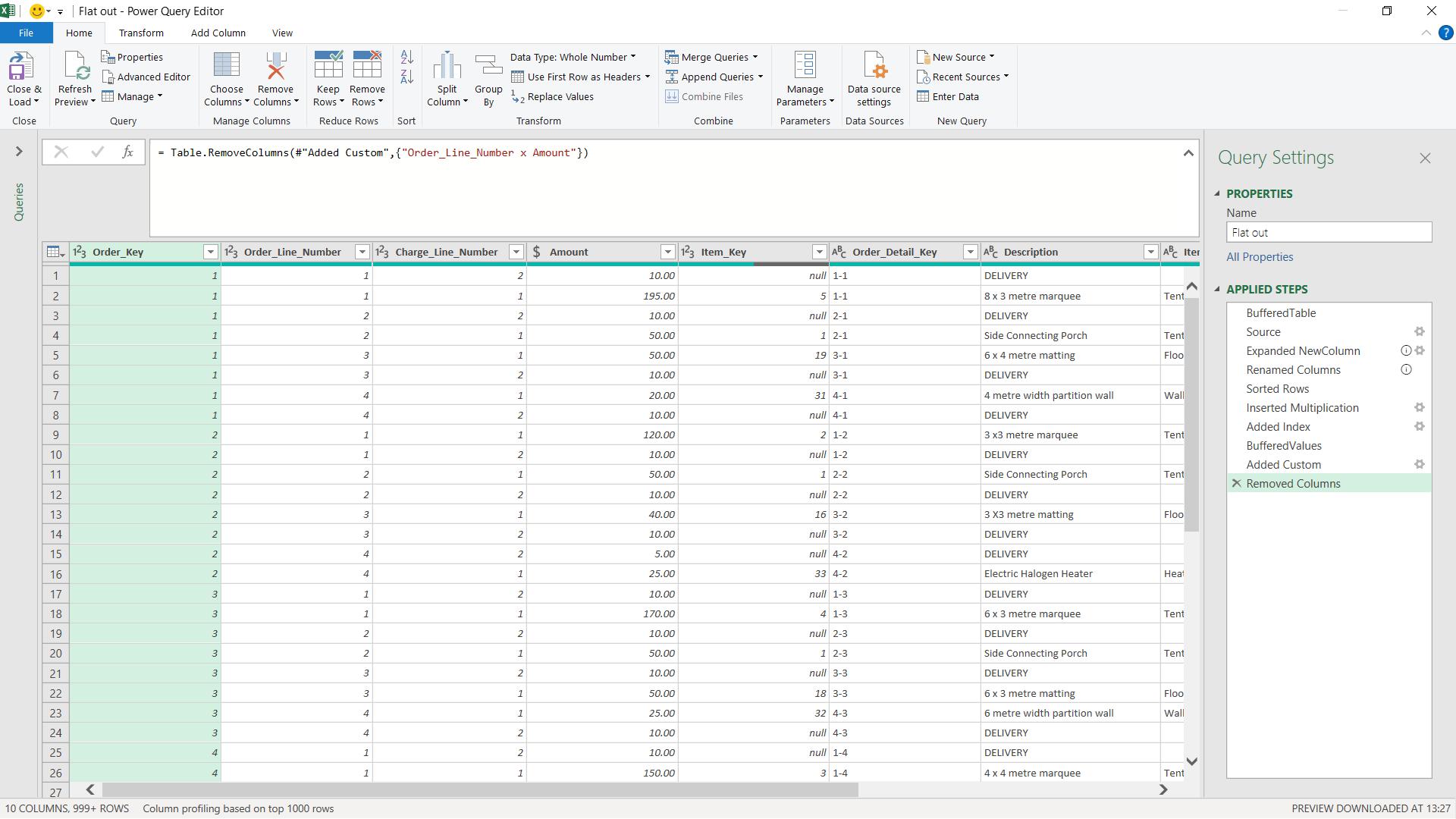
This week, I will consider how I can ensure that my query can be loaded to Power BI Desktop without using excessive memory. I can start with simple considerations. It’s not only pointless to include columns that I won’t be using in my Data Model, it also wastes memory to load them. I choose the columns I want to keep by clicking on them whilst holding down the CTRL key.
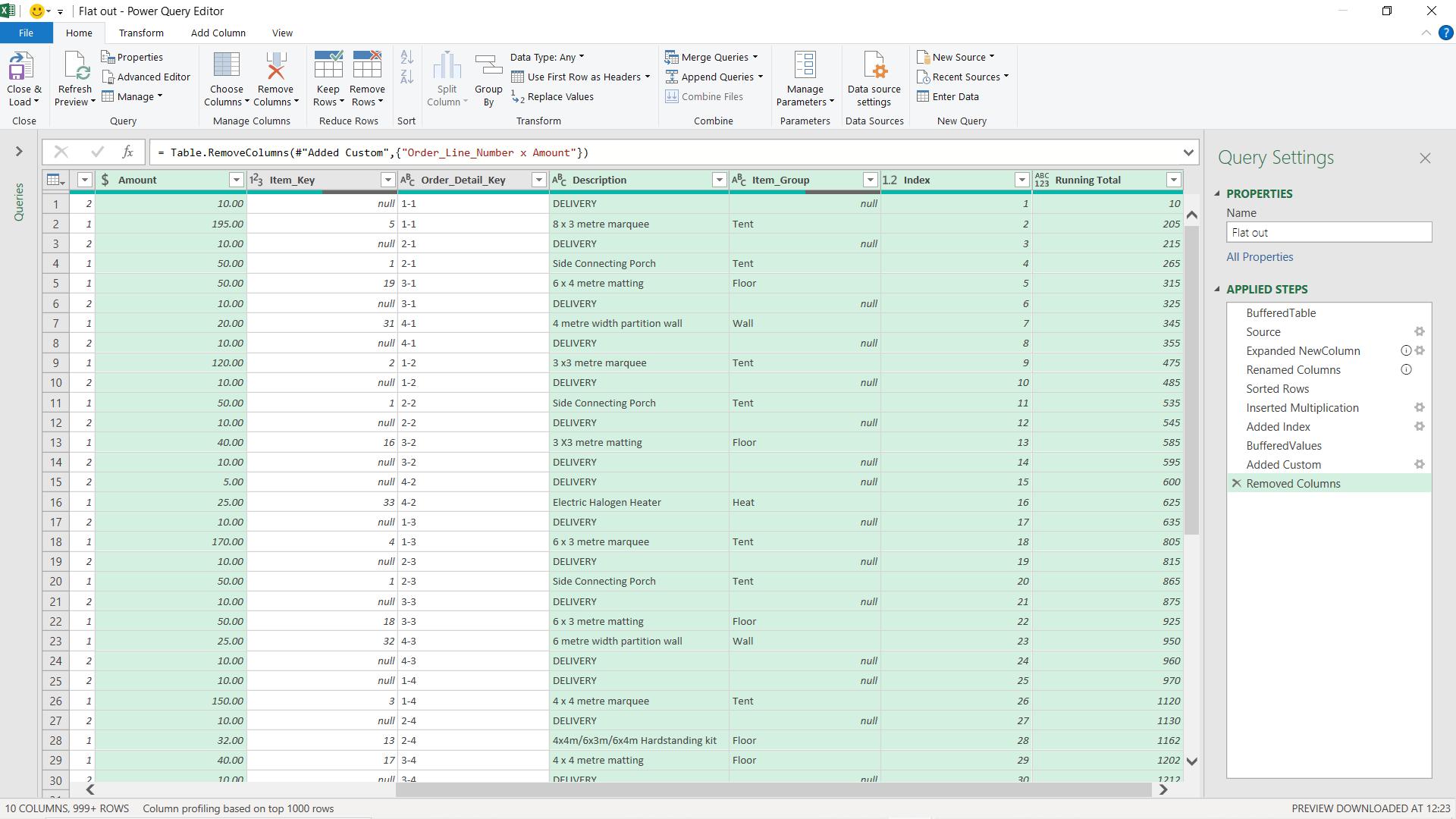
I can now right-click on my group and ‘Remove Other Columns’.
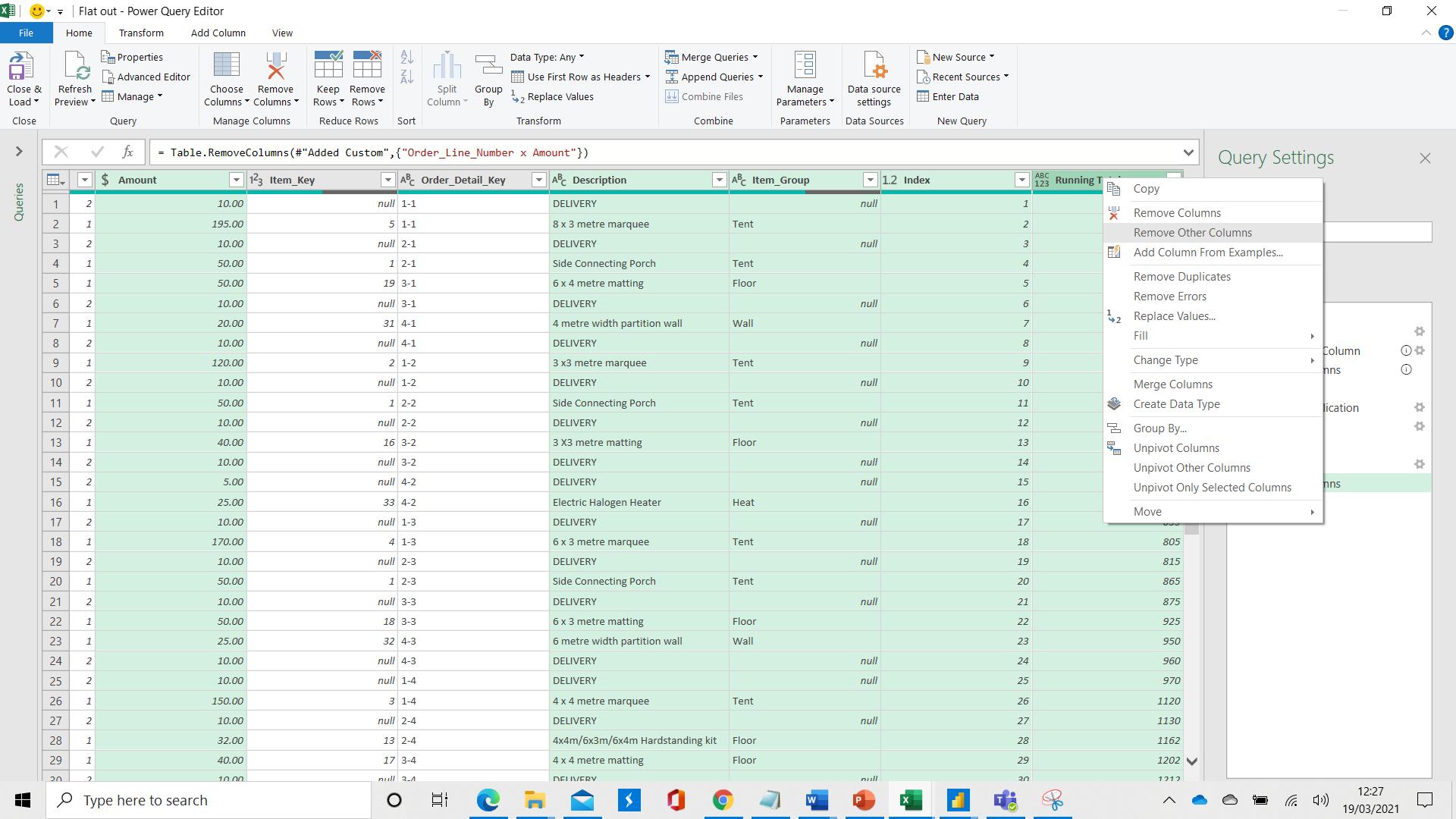
I have to right-click in the column headings to do this, otherwise Power Query thinks I am trying to manipulate one of the values in the table.
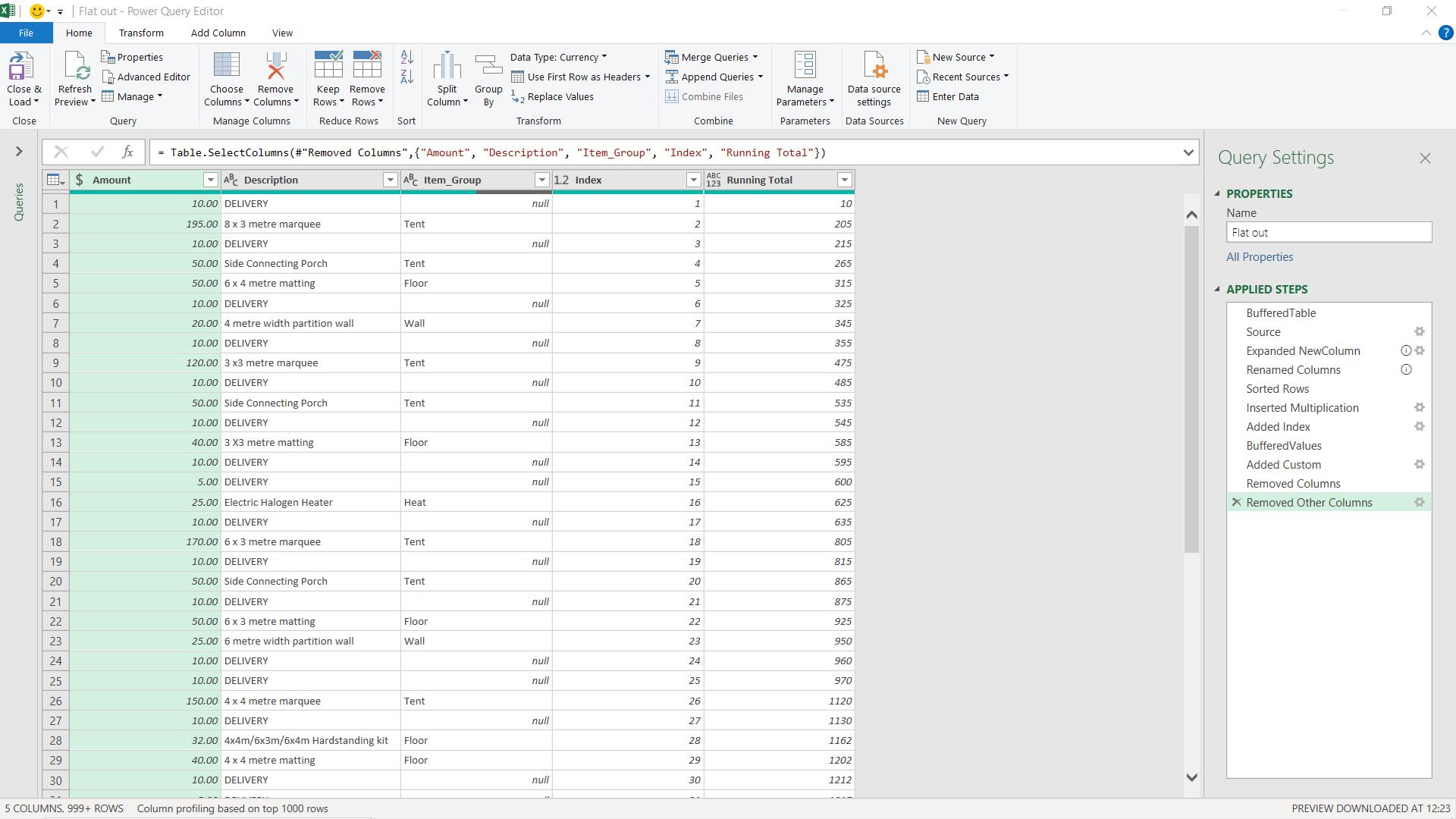
The next point to note is the data type on Running Total. It is currently set to type ‘Any’ which means it is undefined. When loading to Power BI Desktop, this column would be analysed to determine the best type to use there. I can save this processing time by choosing the correct type before I load the data.
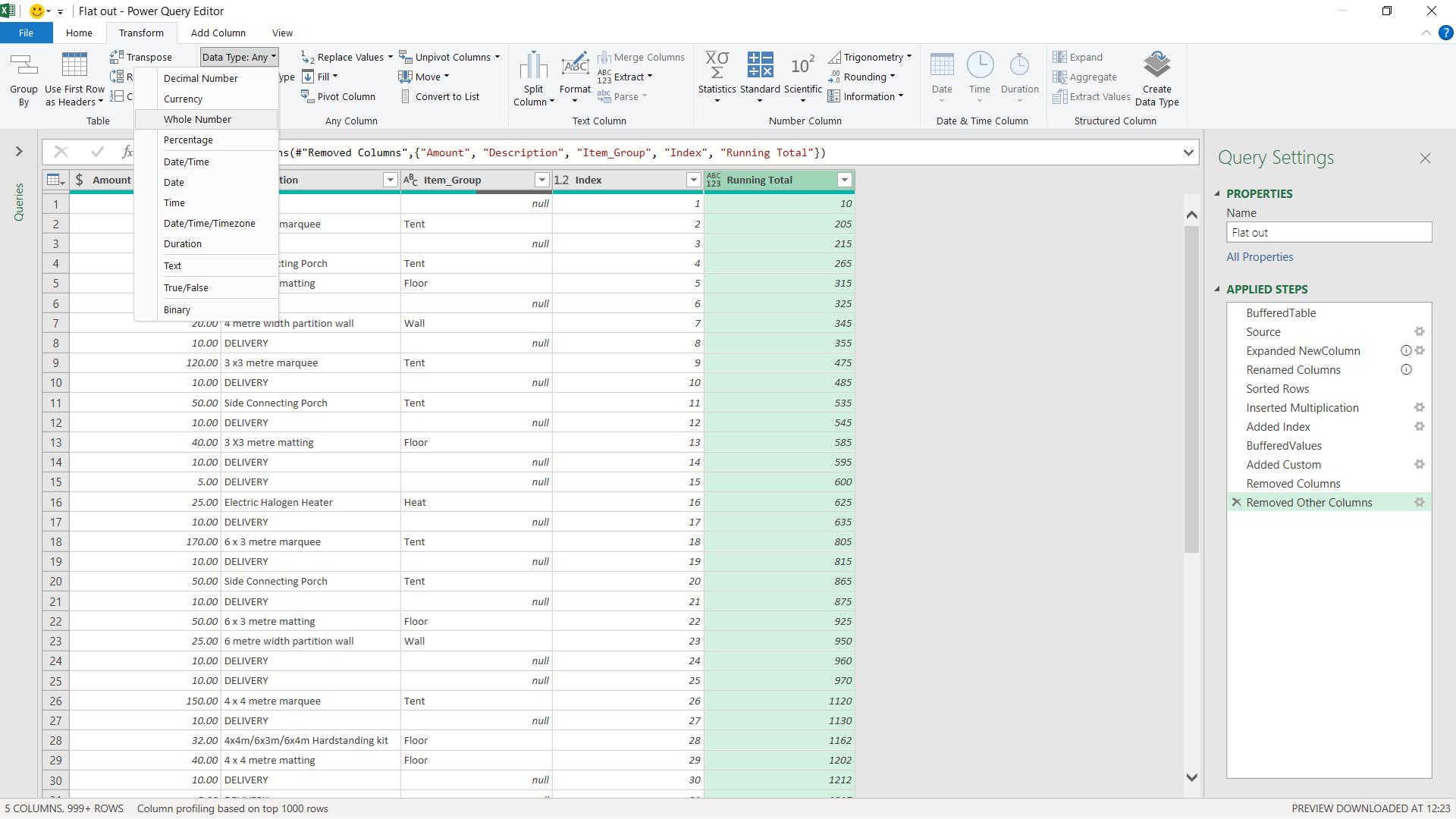
On the Transform tab, I can choose which type to use for my column; I choose to make it a ‘Whole Number’.
Having considered how many columns I need, and what type they are, I should also consider how many rows I am loading to the Data Model. If I don’t need this level of granularity, I can consider grouping my data. This should always be done after I have removed unnecessary columns.
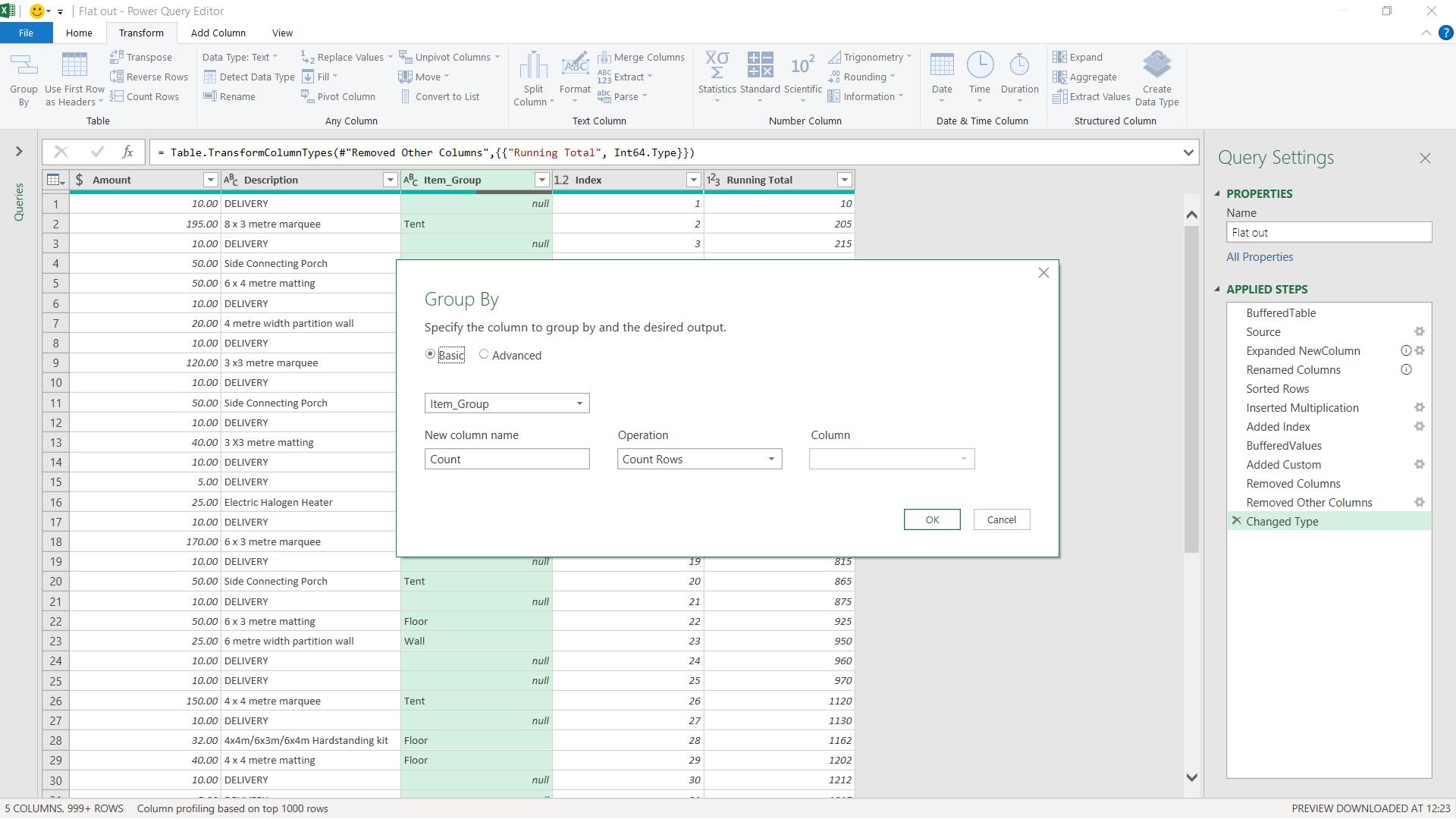
The ‘Group By’ option on the Transform tab defaults to a simple group which would give me two columns, but I also want to sort by and keep Description, so I pick the ‘Advanced’ option.
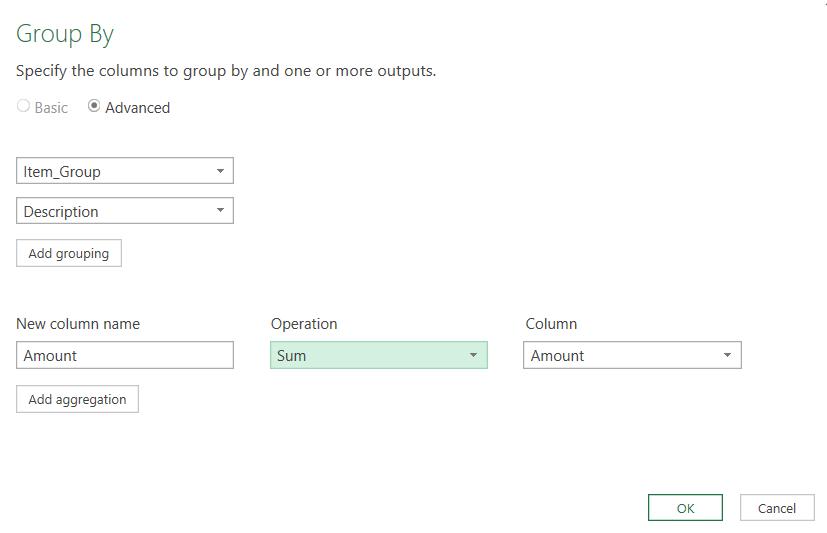
I have chosen to sum the Amount column.
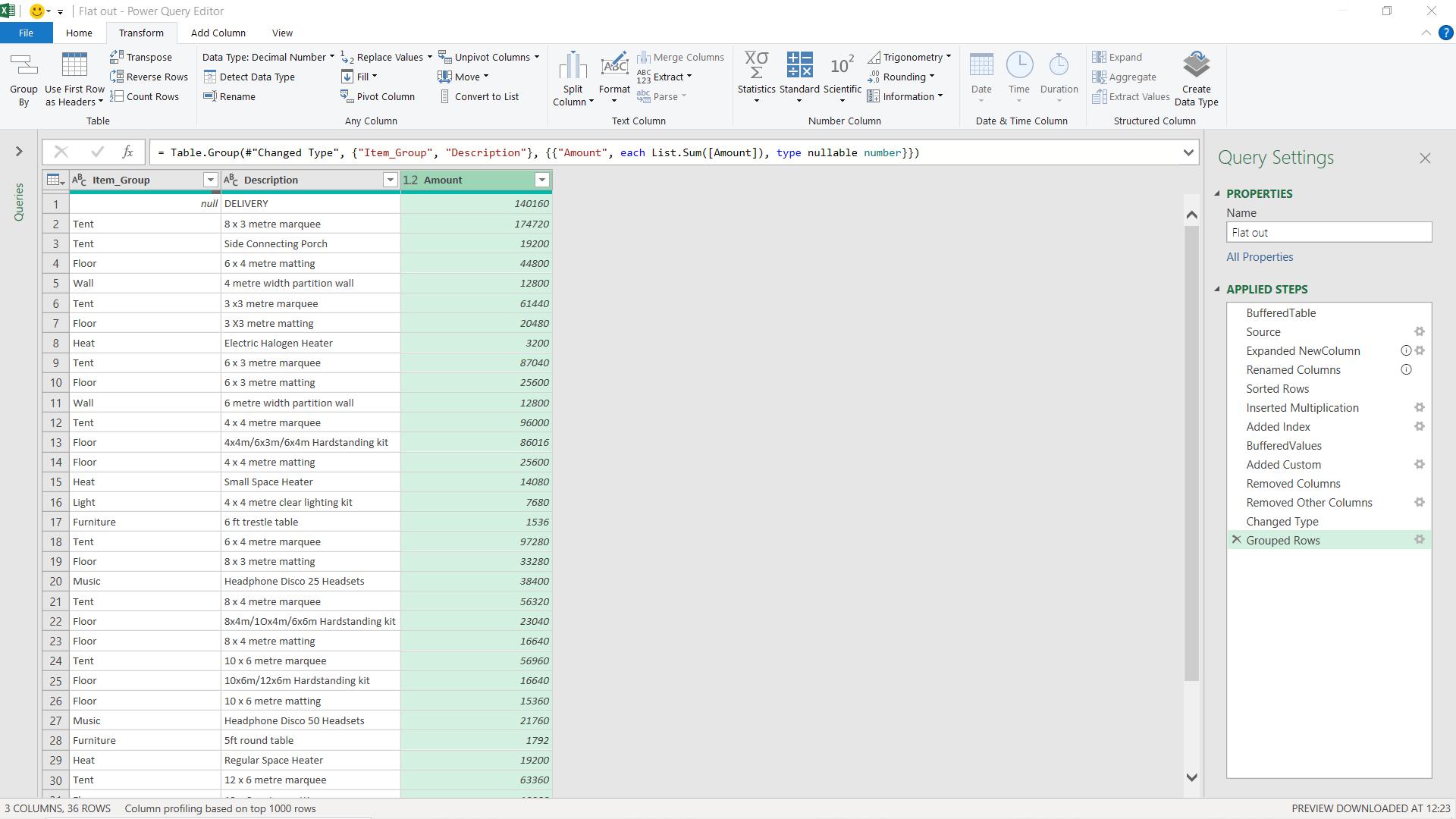
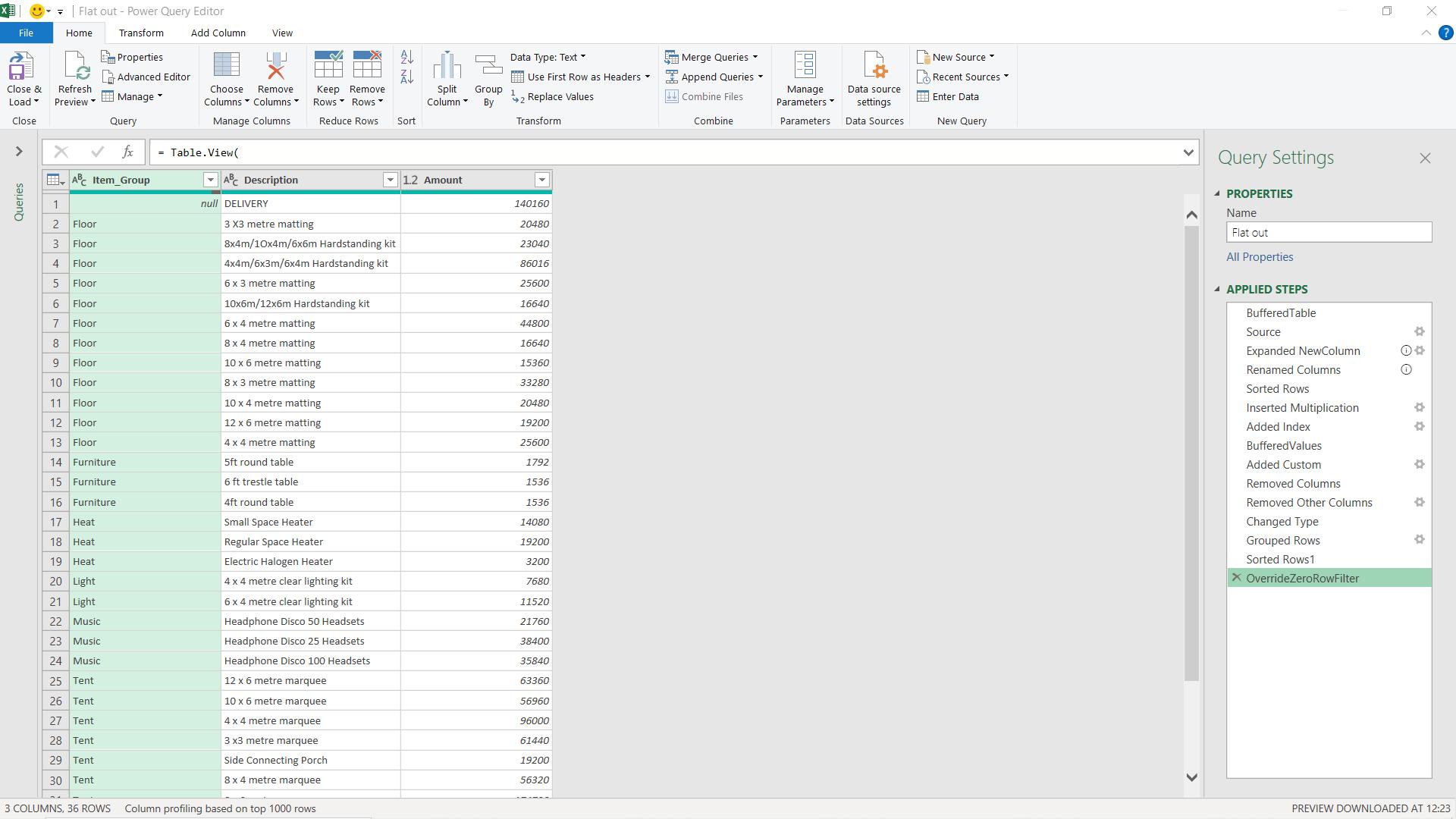
I apply the grouping and I now have 36 rows instead of over 30,000. I just need to sort my data and apply one final step. I will be using the M function Table.View().
Unlike queries that use data from relational databases, my query is not subject to query folding (more on this in a later blog for those who are unsure what this is). Folded queries are accessed once during loading to Power BI Desktop. However, queries using flat files, like mine, are not folded and are accessed twice.
During the load, the query is read once with filters that return with zero rows and just determine the column information. The query is then read with no filter, allowing the rows of data to be loaded into a table in Power BI Desktop.
The trick here is to use the Table.View () function to make the Power Query engine run the zero-row filter read instantly. This will ALWAYS be the last step in the query.
The Table.View () function uses the following syntax:
Table.View(table, handlers) as table,
This function returns a view of the table as specified by the handlers. In this case, the table parameter is set to null, since I am loading the table for the first time, not extending it.
Table.View(null, handlers)
In the handlers section, I provide the column names and column type information which would have been automatically accessed in the zero-row filter read. This means that this step is only run when editing the query, and not when refreshing it. There are three handlers which work together to pass the required information to Power Query:
- GetType is called when the Power Query engine needs to know about the data types of the columns of the table returned by this expression. This is where I need to know all the columns and their types, in order to fully describe the structure of my table. The types used in this query are:
Decimal = Number.Type
Text = Text.Type
Whole number = Int64.Type - GetRows is called when the Power Query engine wants all the rows from the table (for example when it’s loading data into the dataset). In this case I use the previous step name (#"Grouped Rows")
- OnTake is called when the Power Query engine only wants the top n rows from the table. A count of zero [0] means just provide the structure, otherwise the rows from my previous step would be counted.
In this case I shall add the Table.View function to the end of the query to optimise load times. I find the easiest way to do this is to open the Advanced Editor in windows mode, and position it just below the column titles so I can see what the column names are, and what Data Type they are. I add the following code to the last line:
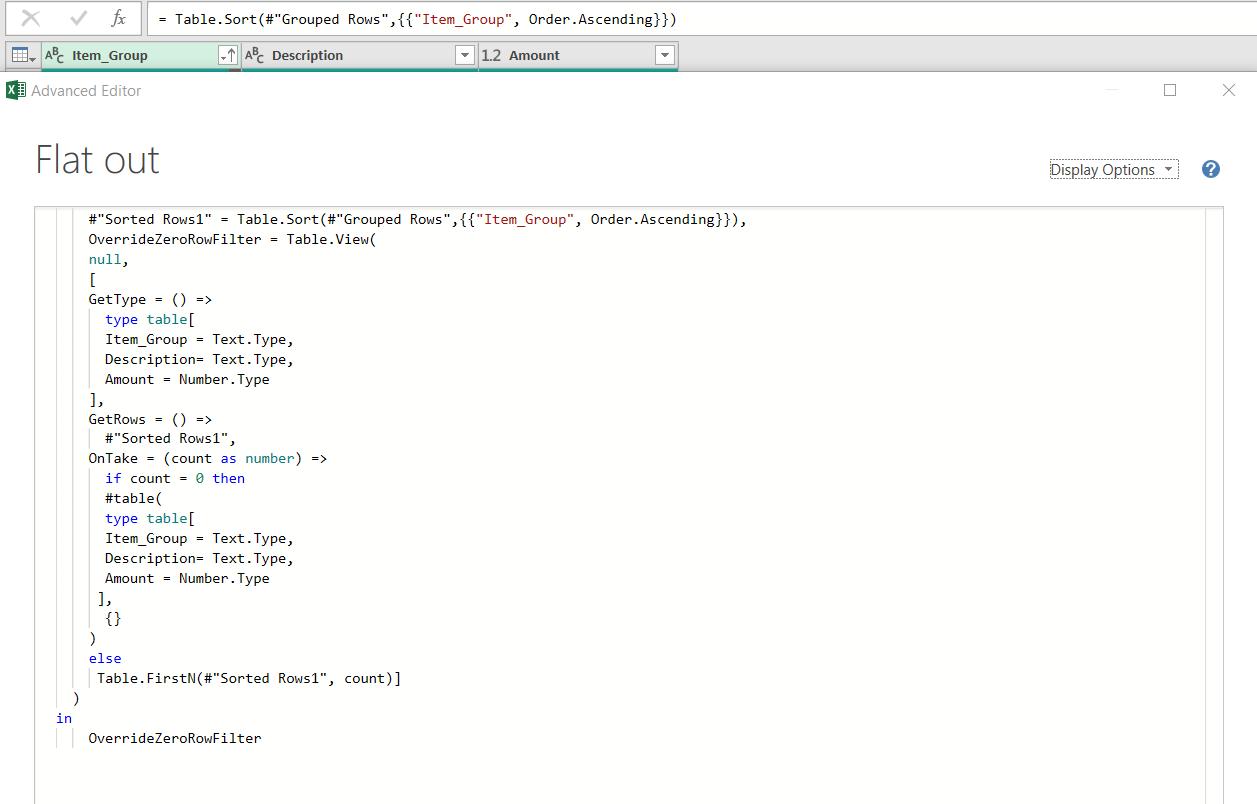
The M code is:
#"Sorted Rows1" = Table.Sort(#"Grouped Rows",{{"Item_Group", Order.Ascending}}),
OverrideZeroRowFilter = Table.View(
null,
[
GetType = () =>
type table[
Item_Group = Text.Type,
Description = Text.Type,
Amount = Number.Type
],
GetRows = () =>
#"Sorted Rows1",
OnTake = (count as number) =>
if count = 0 then
#table(
type table[
Item_Group = Text.Type,
Description = Text.Type,
Amount = Number.Type
],
{}
)
else
Table.FirstN(#"Sorted Rows1", count)]
)
in
OverrideZeroRowFilter
I make any mistakes, I just need to compare the columns before the Table.View() step to the columns for the final step and look for any differences. My query is now ready to load.
Come back next time for more ways to use Power Query!