
Power Pivot Principles: The A to Z of DAX Functions – INTERSECT
29 July 2025
In our long-established Power Pivot Principles articles, we continue our series on the A to Z of Data Analysis eXpression (DAX) functions. This week, we look at INTERSECT.
The INTERSECT function
The INTERSECT function is one function that returns the row intersection of two [2] tables, retaining duplicates. It operates using the following syntax:
INTERSECT(table_expression1, table_expression2)
There is just the one [1] main argument in this function:
- table_expression: this argument is any DAX expression that returns a table.
Here are a few remarks about the INTERSECT function:
- INTERSECT is not commutative. In general, INTERSECT(T1, T2) will have a different result set than INTERSECT(T2, T1) – the next point provides one reason why this may be so
- duplicate rows are retained. If a row appears in table_expression1 and table_expression2, it and all duplicates in table_expression1 are included in the result set
- the column (field) names will match the column names in table_expression1
- the returned table has lineage based upon the columns in table_expression1, regardless of the lineage of the columns in the second table. For example, if the first column of first table_expression has lineage to the base column C1 in the model, the intersect will reduce the rows based on the intersect on first column of second table_expression and keep the lineage on base column C1 intact
- columns are compared based upon positioning and data comparison with no type of coercion
- the returned table does not include columns from tables related to table_expression1
- this function is not supported for use in DirectQuery mode when used in calculated columns or Row-Level Security (RLS) rules.
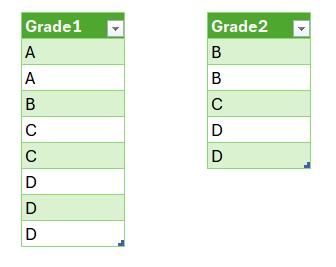
As an example, imagine we have two [2] Tables listing grades:
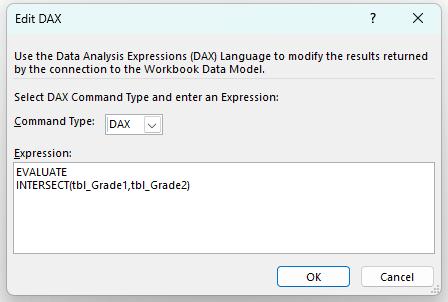
To find the common grades between two Tables, use the INTERSECT function as follows:
This will return a single-row Table showing:
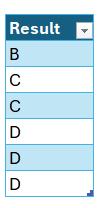
When INTERSECT evaluates these two sets, it returns only the values that exist in both. Although grades like A appear in Grade1, they are excluded from the result because they do not appear in Grade2. Thus, the final output reflects only the grades that are common to both lists.
As we mentioned in the Remarks, INTERSECT is not commutative, meaning the order of the input matters. Therefore, let’s test what happens when we reverse the argument order:
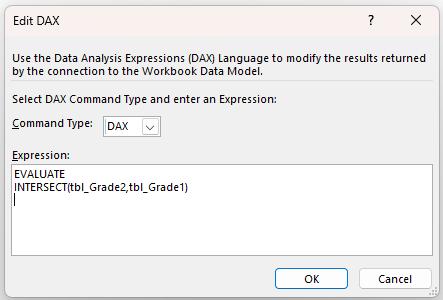
This will return a Table that is different from the result we obtained earlier:
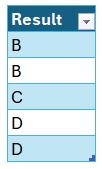
Since Grade1 contains one "B" and Grade2 contains two "B"s, INTERSECT(Grade1, Grade2) returns one "B" (limited by Grade1), while INTERSECT(Grade2, Grade1) returns two "B"s (limited by Grade2). Similarly, the number of occurrences of "D" changes since the order changes.
Thus, the order matters because the number of duplicates in the result depends on how many times each value appears in the first table, filtered by existence in the second.
Come back next week for our next post on Power Pivot in the Blog section. In the meantime, please remember we have training in Power Pivot which you can find out more about here. If you wish to catch up on past articles in the meantime, you can find all of our Past Power Pivot blogs here.