
Power Pivot Principles: The A to Z of DAX Functions – INDEX
23 April 2024
In our long-established Power Pivot Principles articles, we continue our series on the A to Z of Data Analysis eXpression (DAX) functions. This week, we look at INDEX.
The INDEX
function

The INDEX function in DAX is quite versatile and allows users to retrieve a specific row from a table based upon its position within a sorted partition. It employs the following syntax:
INDEX(position[, relation or axis][, orderBy][, blanks][, partitionBy][, matchBy] [, reset])
This function has six [6] arguments:
- position: the desired row position (1-based) within the sorted
partition (1-based), being:
- if the typed position is positive: 1 refers to the first row, 2 is the second row, etc.
- if the typed position is negative: -1 refers to the last row, -2 is the second last row, etc.
When position is out of the boundary, zero or BLANK(), INDEX will return an empty table. It can be any DAX expression that returns a scalar value
- relation: an optional argument, this is the table (or
expression) containing the data. We can
specify multiple columns, but they must all belong to the table we're working
with or a related one. If this argument
is omitted, it has with two [2] conditions:
- we must tell the function how to order the data (orderBy)
- all columns used for ordering and partitioning (orderBy and partitionBy) must be clearly linked to a table (“fully qualified”) and come from the same table.
- axis: this is an optional alternative to relation, and represents an axis in the visual shape. It is available in visual calculations only
- orderBy: an optional argument containing the expressions that define how each partition is sorted. If omitted, the relation argument must be explicitly specified and defaults to ordering by every column in relation that is not already specified in partitionBy
- blanks: optional argument that is reserved for future use. An enumeration that defines how to handle blank values when sorting. Currently, the only supported value is DEFAULT, where the behaviour for numerical values is blank values, which are ordered between zero and negative values. The behaviour for strings is that blank values are ordered before all strings, including empty strings
- partitionBy: optional argument. If is used, the data is divided into separate partitions based upon the specified column, otherwise, the entire table is considered as a single partition
- matchBy: optional argument that helps to define how the current row is identified
- reset: this is also an optional argument
and is only available in visual calculations. It indicates if the calculation resets, and at
which level of the visual shape's column hierarchy. Accepted values are: NONE, LOWESTPARENT, HIGHESTPARENT or an integer. The
behaviour depends upon the integer sign:
- if zero or omitted, the calculation does not reset. This is equivalent to NONE
- if positive, the integer identifies the column starting from the highest, independent of grain. HIGHESTPARENT is equivalent to 1
- if negative, the integer identifies the column starting from the lowest, relative to the current grain. LOWESTPARENT is equivalent to -1.
The key purposes of INDEX are as follows:
- retrieve a single row from a table based on its position or other specifications, even if multiple rows match the criteria due to sorting or partitioning
- identifies the row based on its position (index) within a partition
- the partition is defined by specific columns we choose (optional)
- we can also specify the sorting order for rows within the partition
- filter and identify specific data points within a larger dataset
- used for creating dynamic calculations and comparisons.
Common use cases in DAX include:
- ranking: find the row with a specific rank within a group (e.g. top five [5] customers by sales in each region)
- INDEX can be combined with other DAX functions for complex calculations
- it can be used within CALCULATE or other iterating functions for dynamic calculations
- comparisons: compare values from different rows within the same partition (e.g. current month sales vs. previous month for each product)
- conditional calculations: perform calculations based upon specific row positions within partitions
- data manipulation: create new tables based upon specific row selections from different partitions.
There are several remarks:
- each partitionBy and matchBy column must have a
corresponding outer value to help define the “current partition” on which to
operate, with the following behaviour:
- if there is exactly one corresponding outer column, its value is used
- if there is no corresponding outer column
- INDEX will first determine all partitionBy and matchBy columns that have no corresponding outer column
- for every combination of existing values for these columns in INDEX’s parent context, INDEX is evaluated and a row is returned
- INDEX’s final output is a union of these rows
- if there is more than one corresponding outer column, an error is returned
- if matchBy is present, INDEX will try to use matchBy and partitionBy columns to identify the row
- if matchBy is not present and the columns specified within orderBy and partitionBy cannot uniquely identify every row in relation:
- INDEX will try to find the least number of additional columns required to uniquely identify every row
- if such columns can be found, INDEX will automatically append these new columns to orderBy and each partition is sorted using this new set of orderBy columns
- if such columns cannot be found, an error is returned
- an empty table is returned if:
- the corresponding outer value of a partitionBy column does not exist within relation
- the position value refers to a position that does not exist within the partition
- if INDEX is used within a calculated column defined on the same table as relation and orderBy is omitted, an error is returned
- reset can be used in visual calculations only, and cannot be used in combination with orderBy or partitionBy. If reset is present, axis can be specified but relation cannot; the final output is a union of these rows
- the search within each partition based on MATCHBY is case-sensitive by default. Use SEARCH for case-insensitive matching
- if orderBy is not specified, the sorting order may vary depending on the data source and can lead to different results
- when using multiple arguments, ensure compatibility of data types and avoid ambiguous references
- consider error handling using ISBLANK or other functions to prevent errors in case no matching row is found
- INDEX function is not compatible with Excel and currently it is only compatible with Power BI, SSAS Tabular, Azure AS and SSDT.
Let’s consider the following table call TB_Sales. Imagine we want to retrieve the third [3rd] Category with best sales in this Table:
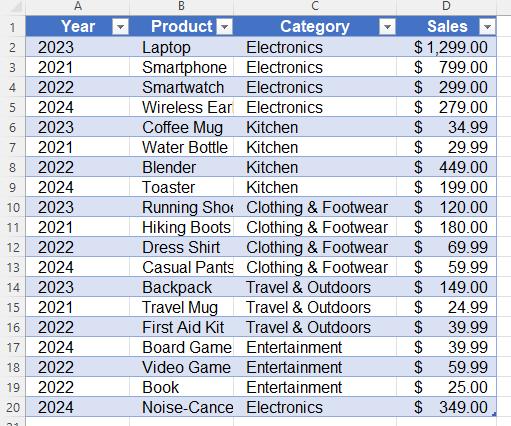
EVALUATE
VAR SalesByCategory =
ADDCOLUMNS (
ALL ( 'TB_Sales'[Category] ),
"Sales",[Total Sales]
)
RETURN
INDEX (
3,
SalesByCategory,
ORDERBY ( [Sales], DESC )
)
This returns the following output:

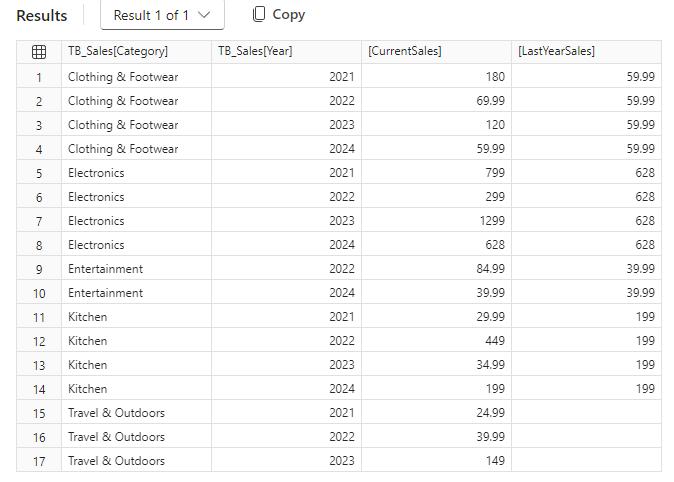
Let’s consider another example here. Imagine that we want to retrieve data from the latest year:
EVALUATE
SUMMARIZECOLUMNS (
TB_Sales[Category],
TB_Sales[Year],
FILTER (
VALUES(TB_Sales[Year]),
[Year] > 2020
),
"CurrentSales", [Total Sales],
"LastYearSales",
CALCULATE (
[Total Sales]
,INDEX(-1, ORDERBY(TB_Sales[Year]))
)
)
ORDER BY TB_Sales[Category],TB_Sales[Year]
This returns the following output:
Come back next week for our next post on Power Pivot in the Blog section. In the meantime, please remember we have training in Power Pivot which you can find out more about here. If you wish to catch up on past articles in the meantime, you can find all of our Past Power Pivot blogs here.