
Power Pivot Principles: The A to Z of DAX Functions – DISTINCT(column)
9 May 2023
In our long-established Power Pivot Principles articles, we continue our series on the A to Z of Data Analysis eXpression (DAX) functions. This week, we look at DISTINCT(column).
The DISTINCT(column) function
The DISTINCT(column) function is one of the table manipulations functions that returns a one-column table containing the distinct values from the specified column. This means that the duplicate values are removed, and only unique values are returned. It has the following syntax:
DISTINCT(column)
It has only one [1] argument:
- column: this is required and represents the column from which unique values are to be returned or an expression that returns a column.
Here are a few remarks about this function:
- the current filter context has an impact on the results of the DISTINCT(column) function
- this function is not supported for use in DirectQuery mode when used in calculated columns or row-level security (RLS) rules
- there is another version of the DISTINCT(column) function which is the DISTINCT(table) function. The latter function removes the duplicate rows for another table or expression
- similar to the DISTINCT (column) function, the VALUES function will also return a list of unique values and generally will produce the same result as the DISTINCT function. However, in some contexts, the VALUES function will return additional value(s)
- another function that also return the unique list of value is the ALL function.
As an example, we have the following dimension (dim) table named Customer (data is displayed in full):

We will write the following DAX code to extract the unique list of Customer Group:

It will return the following table:
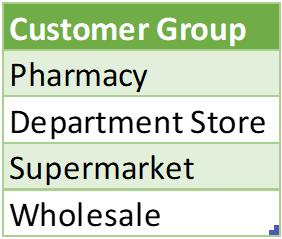
Next, we will test out the VALUES function which we expect to give out a similar result, so we write the following DAX code:


This time, the VALUES function provides us with an extra empty cell in the results. The condition for this empty cell to appear is that:
- one to many relationships between the dimension (dim) and factual (fact) tables
- there is one or more matching keys in the fact table that does not exist in the dim table.
In this case, our fact table, which is Sales, had a CustomerKey that did not have any match with any record in the CustomerKey in the Customer table.
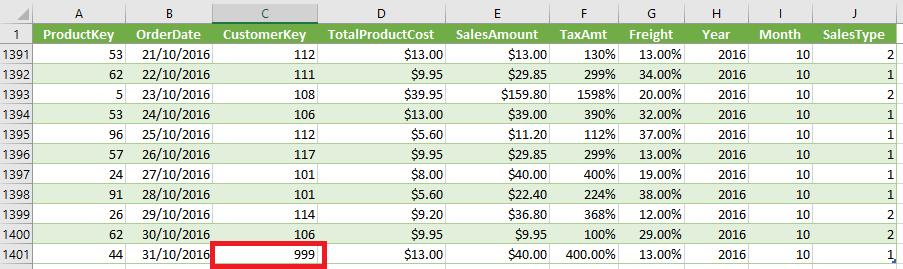
As we can see here, the CustomerKey 999 does not exist
in the Customer dimension table. Hence,
the VALUE function adds one blank row to match all the unmatched values,
whilst the DISTINCT function only returns values that exists in the
original dimension table resulting in no empty cells.
Moving on to another example with the ALL function:

This gives us a similar result to the DISTINCT function:
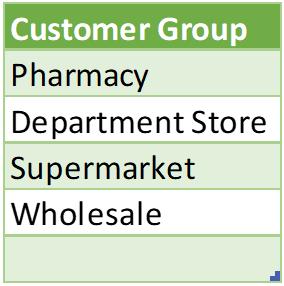
There is a difference between the DISTINCT, VALUE and ALL functions. Let’s consider another example to understand the key differences between these functions. We can write the following DAX code in 'Edit DAX':
EVALUATE
SUMMARIZECOLUMNS(
Customer[Customer Group],
"DISTINCT" , COUNTROWS(DISTINCT(Customer[CustomerKey])),
"VALUES" , COUNTROWS(VALUES(Customer[CustomerKey])),
"ALL" , COUNTROWS(ALL(Customer[CustomerKey]))
)

This code essentially groups everything into the Customer Group then we may count how many unique records in CustomerKey each function generates for each Customer Group. In summary:
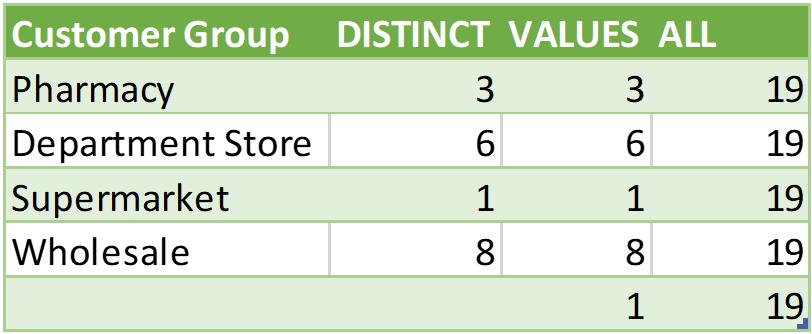
The ALL function returns 19 for the Customer Group because this function ignores the current filter context and always returns the complete unique list even for an empty value cell. Whilst the VALUES function returns an extra empty cell as discussed in above example, the DISTINCT function will derive the unique list of the current table.
Come back next week for our next post on Power Pivot in the Blog section. In the meantime, please remember we have training in Power Pivot which you can find out more about here. If you wish to catch up on past articles in the meantime, you can find all of our Past Power Pivot blogs here.