
Power Pivot Principles: Bidirectional Relationships in Power Pivot
18 February 2020
Welcome back to the Power Pivot Principles blog. This week, we are going to talk about relationships in Power Pivot.
There are three different possible physical relationship types in database design but not all supported in Power Pivot. The major types of relationship are:
- one-to-many
- one-to-one
- many-to-many.
Only one-to-many is supported in Power Pivot. Let’s look at one simple example.
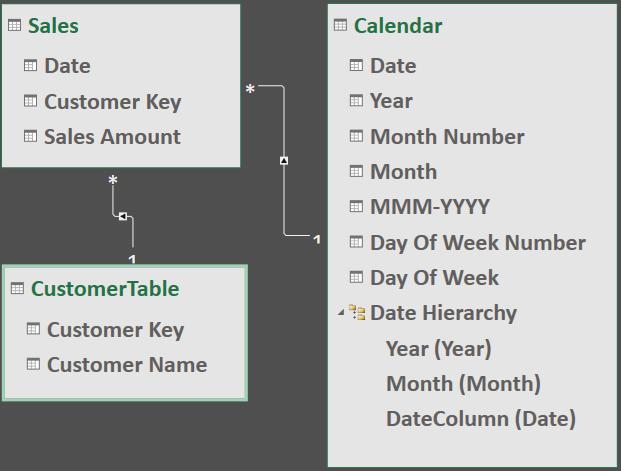
A relationship can be set up as unidirectional (i.e. flowing in one direction, the default behaviour) or bidirectional (i.e. flowing in both directions). In a unidirectional relationship the filter context is propagated from the one-side to the many-side, but not the other way around. As the foundation of Power Pivot, the one-to-many relationship is a typical unidirectional relationship. In the example above, the Customer table is on the 1 side of the relationship and the Sales table is on the many side of the relationship (i.e. we may make more than one sale to the same customer). In this case, we use a common field ‘Customer Key’ to join both tables. ‘Customer Key’ here is used as unique code that helps to identify each customer name. No duplicates of the Customer Key are allowed in the Customer table. On the other side, in the Sales table, ‘Customer Key’ may be used many times if there are multiple records of sales for specific customers. This is how one-to-many relationships are defined between dimension tables (lookup tables commonly on the one (1) side of the relationship) and fact tables (known as the factual data tables on the many side of the relationship). The entire Power Pivot Vertipaq engine is optimised to work with this (one to many) type of relationship.
Let’s take a closer look at the ‘Edit Relationship’ dialog in Power Pivot:
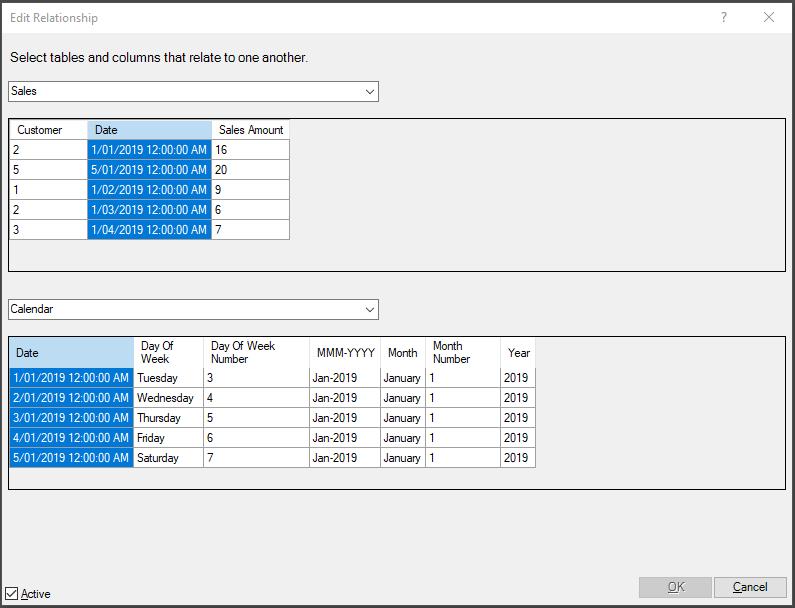
We set up the relationship between the Sales table and the Calendar table, based upon the attribute Date. However, it should be noticed that in Power Pivot, only one-to-many relationships are available, and no bidirectional filter is allowed in the editor. Fortunately, the DAX engine in Excel 2016 facilitates DAX codes to achieve the effect of a bidirectional filter. The DAX function CROSSFILTER adds a third argument that provides the ability to modify the direction of propagation of the filter in a relationship. Available arguments include None, OneWay and Both. We will consider this function later.
Let’s have a look at the case in Power BI. Bidirectional relationships are supported in Power BI since sometimes BI developers want to synchronise slicers for data analysis. Let’s look at a simple example. We have four (4) tables and relationships setup as shown below (numbers indicates the fields link):
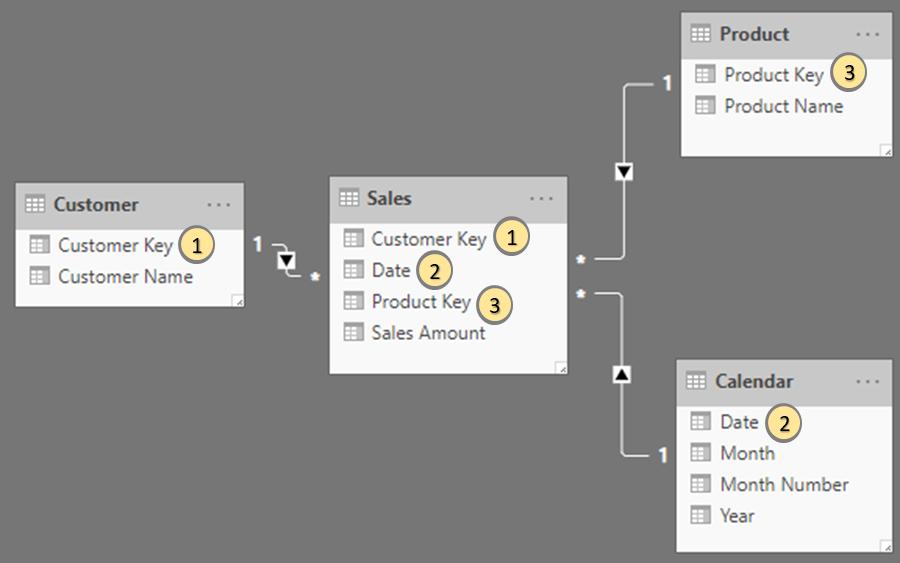
The Sales table is filtered by the Customer table on ‘Customer Key’ and the Product table is filtered on ‘Product Key’ with a unidirectional one-to-many relationship. We create the summary of sales based upon the data and relationships above. In this instance, the result would be:
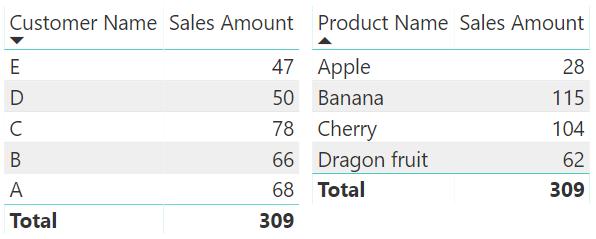
This behaviour works fine in most scenarios. It is quite common to filter sales based upon customers or products’ attributes. If we want to use two slicers (one for the customer name and one for the product name) to filter the sales, the result table would be:
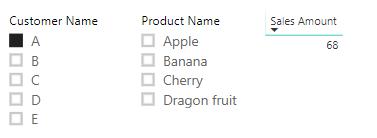
The report works as we expected. It filters the sales by customer A. However, the ‘Product Name’ slicer does not work properly. For example, customer A only accounts for the sale of product Cherry and Dragon fruit, but product Apple and Banana remain on the slicer list. Therefore, the slicer ‘Product Name’ does not provide easy feedback to the end users. The reason is simple: the filter on Customer reaches Sales, so it only filters the sales of the selected customer. However, the filter does not automatically flow from the Sales table to the Product table because of the unidirectional relationship. If we want to filter Product based upon Customer, we can change the relationship between Product and Sales to a bidirectional relationship:
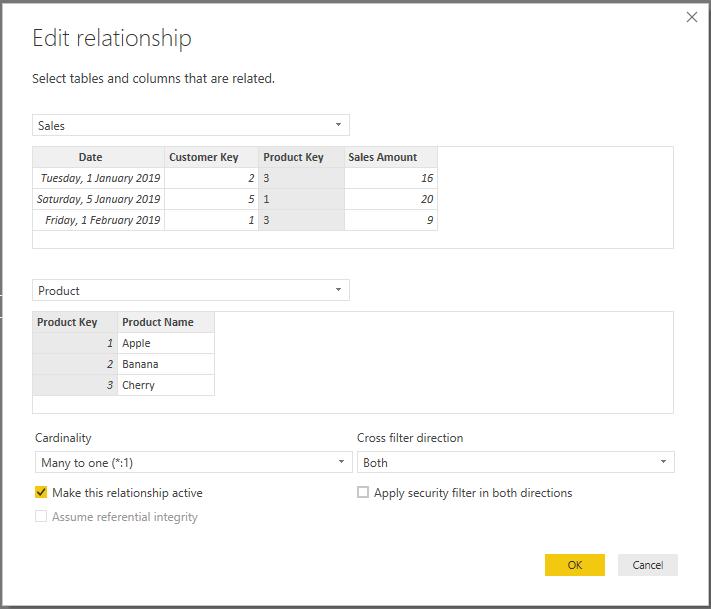
and the relationship diagram should be:
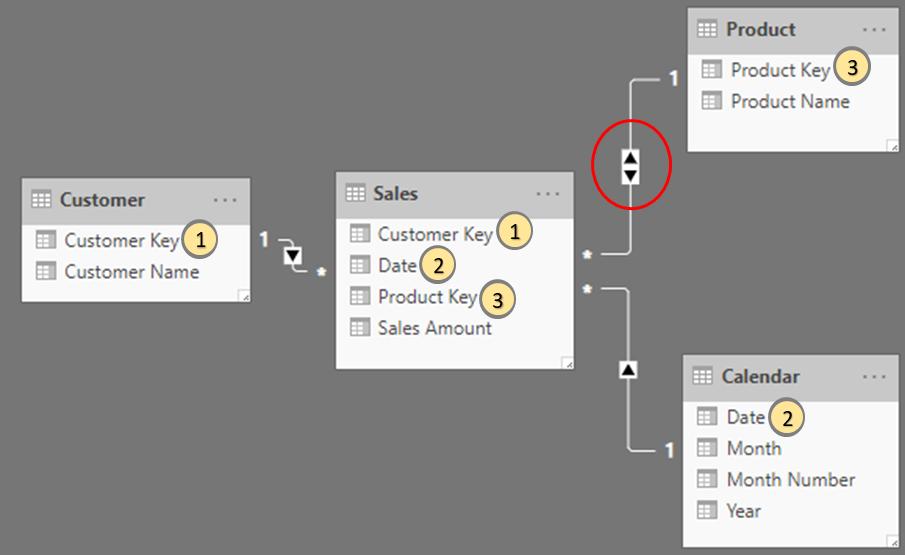
With bidirectional settings, the filter automatically propagates from Sales to Product, so that the slicer ‘Product Name’ will be extended to selected customer which means when we filter on the customer slicer, the filter will be applied to product as well. The result would be:
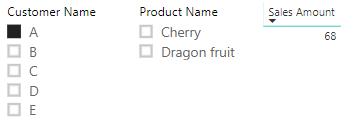
For the purpose of synchronising slicers in Power BI, bidirectional filter is simple and straightforward. However, this filter will also increase the complexity and unpredictability of the data model. The reason is that bidirectional filter introduces ambiguous behaviour in the data modelling. The engine has multiple pathways for transferring a filter from one table to another and it may raise errors when preferred pathway is not found. It will be further illustrated in our future Power BI blog.
As a summary, bidirectional filters can be setup in Power BI for syncing slicers, but it is not possible in Power Pivot at the Data Model level.
That’s it for this week!
Stay tuned for our next post on Power Pivot in the Blog section. In the meantime, please remember we have training in Power Pivot which you can find out more about here. If you wish to catch up on past articles in the meantime, you can find all of our Past Power Pivot blogs here.