
Power BI Blog: Xenagogue to Markup Lists - Part 1
11 April 2018
Welcome back to Power BI Tips.
XML (eXtensible Markup Language) is a free format for information identification, storage and transfer written in mark-up language. It is used to describe data for exchange between applications. Many web applications use XML as it is a standardised format that applications can easily interpret for usage. A lot of RSS (syndication) feeds are in XML.
XML documents form a tree structure that starts at "the root" and branches to "the leaves". The branches define the structure of the data and the leaves represents the data itself.

Today let’s experiment with getting data from the Reserve Bank of Australia RSS feed which is transmitted in XML format.
However, parsing through file takes a little skill. Opening up the link in a browser shows this:
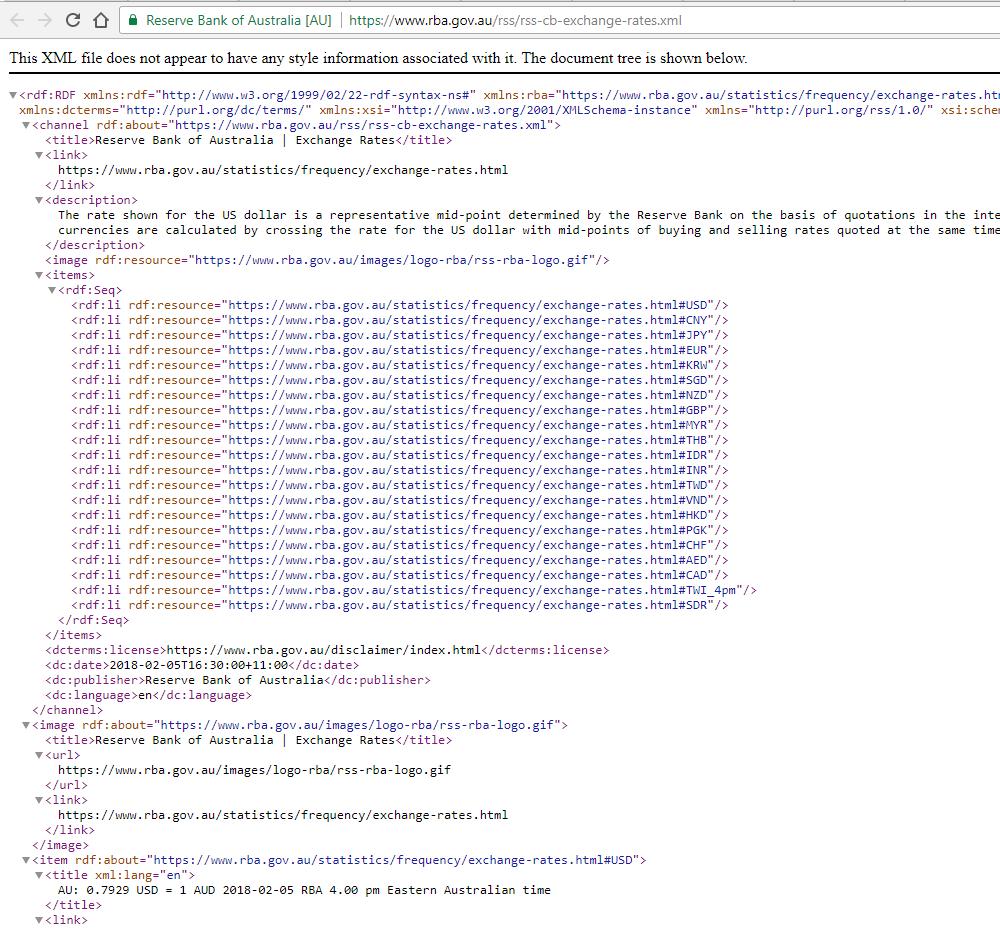
It’s a lot of text. But it’s worth going through the file, in order to find where the items you need sit.
The information we need seems to appear here:

It’s important here to note the hierarchy of how the data is stored for us to navigate and drill down.

From the initial document we drill down the structure of the data as follows:
<item> -> <description> -> <cb:statistics> -> <cb:exchangeRate>
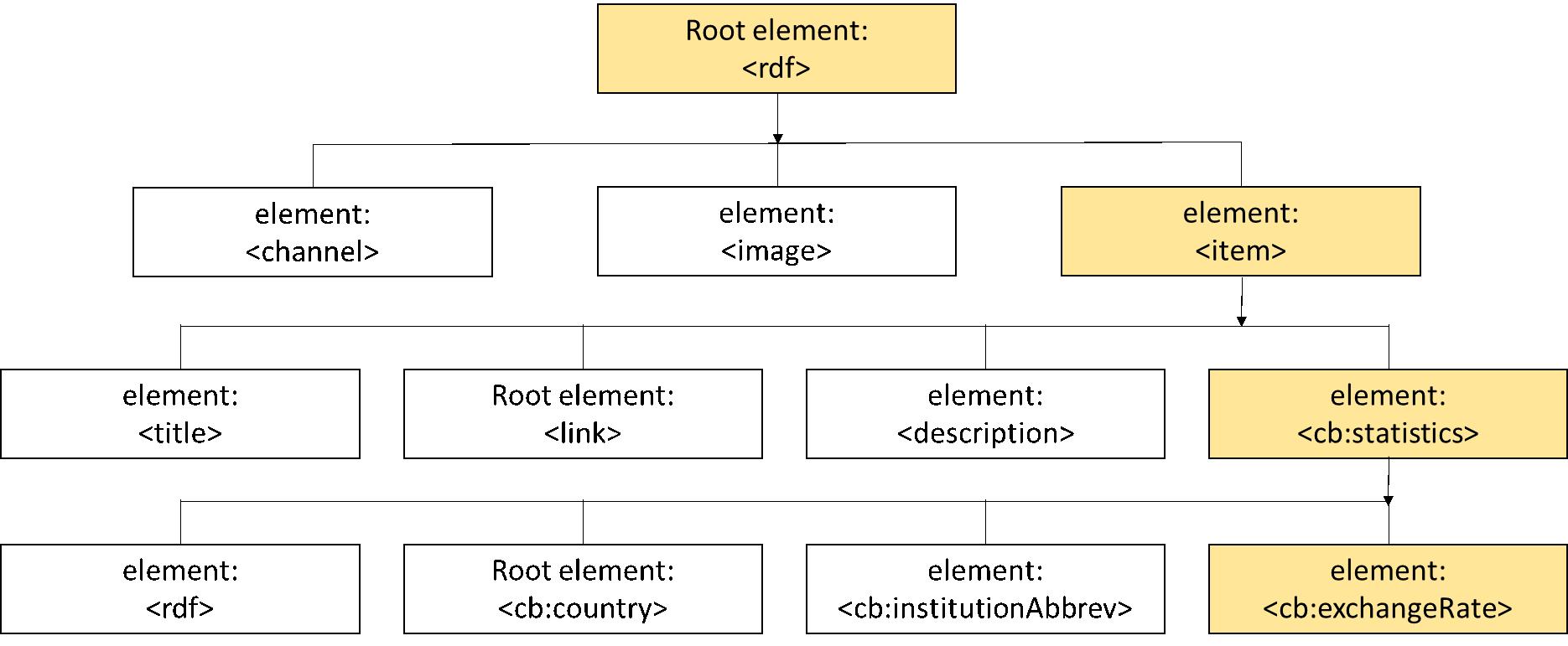
Note here that the order is very important. We will know which branch to go down because it will follow the top down structure of the document.
Let’s “Get Data” and chose “XML”:
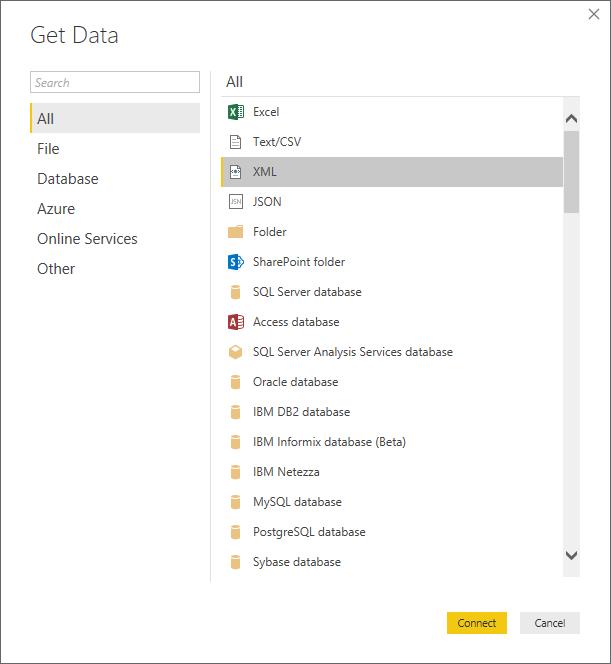
The file dialogue will come up, but since we are using a web-based XML, simply copy the XML address into the “File name” text box.

The “Navigator” screen will come up with the structure of the data:

Expand the "purl.org/rss/1.0 [3]" as that is the first root element of the document, we’ll see the <item> section.

As expected, it’s the 3rd branch.
Hit “Edit” to prepare the data - but we'll cover all the steps in transforming this into a proper table using the Query Editor next time.
Tune in next week for more Power BI Tips!