
A to Z of Excel Functions: The F.INV.RT Function
8 April 2019
Welcome back to our regular A to Z of Excel Functions blog. Today we look at the F.INV.RT function.
The F.INV.RT function
The F-distribution is defined as a continuous distribution obtained from the ratio of two chi-square distributions and used in particular to test the equality of the variances of two normally distributed variances a continuous probability distribution, which means that it is defined for an infinite number of different values. This analysis of variance is often referred to as “ANOVA”, which I still think is a cheap car.
In slightly simpler terms, the F-distribution can be used for several types of applications, including testing hypotheses about the equality of two population variances and testing the validity of what is known as a multiple regression equation, i.e. a formulaic attempt to model the relationship between two or more explanatory variables and a response variable by fitting a linear equation to observed data.
The F-distribution shares one important property with the Student’s t-distribution: probabilities are determined by a concept known as degrees of freedom. Unlike the Student’s t-distribution, the F-distribution is characterized by two different types of degrees of freedom: numerator and denominator degrees of freedom.
The F-distribution has two important properties:
- It’s defined only for positive values.
- It’s not symmetrical about its mean; instead, it’s positively skewed.
A distribution is positively skewed if the mean is greater than the median (the mean is the average value of a distribution, and the median is the midpoint; half of the values in the distribution are below the median and half are above). This function returns the (right-tailed) F probability distribution (degree of diversity) for two datasets.
This distribution is a relatively new one. The associated F statistic is a ratio (a fraction). There are two sets of degrees of freedom; one for the numerator and one for the denominator. As mentioned above, the F distribution is derived from the Student’s t-distribution. The values of the F distribution are squares of the corresponding values of the t-distribution.
To calculate the F ratio, two estimates of the variance are made:
- Variance between samples: An estimate of σ2 that is the variance of the sample means multiplied by n (when the sample sizes are the same). If the samples are different sizes, the variance between samples is weighted to account for the different sample sizes. The variance is also called variation due to treatment or explained variation
- Variance within samples: An estimate of σ2 that is the average of the sample variances (also known as a pooled variance). When the sample sizes are different, the variance within samples is weighted. The variance is also called the variation due to error or unexplained variation:
- SSbetween = the sum of squares that represents the variation among the different samples
- SSwithin = the sum of squares that represents the variation within samples that is due to chance.
To find a “sum of squares” means to add together squared quantities that, in some cases, may be weighted. MS means “mean square”. MSbetween is the variance between groups, and MSwithin is the variance within groups.
To calculate the sum of squares and the mean square, let:
- k = the number of different groups
- nj = the size of the jth group
- sj = the sum of the values in the jth group
- n = total number of all the values combined (total sample size: ∑nj)
- x = one value: ∑x = ∑sj
- The sum of squares of all values from every group combined: ∑x2
The between group variability is therefore
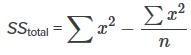
and the total sum of squares is given by
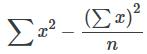
The explained variation is therefore the sum of squares representing variation among the different samples:
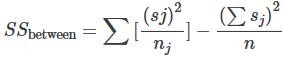
This should be compared with the unexplained variation, namely the sum of squares representing variation within samples due to chance:
SSwithin=SStotal?SSbetween
The degrees of freedom for different groups (i.e. the degrees of freedom for the numerator) is calculated as df = k – 1, whereas the equation for errors within samples (degrees of freedom for the denominator) is calculated as dfwithin = n – k.
Further, the mean square (variance estimate) explained by the different groups is
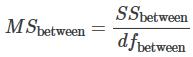
whereas the mean square (variance estimate) that is due to chance (unexplained) is
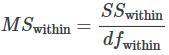
MSbetween and MSwithin can be written as follows:
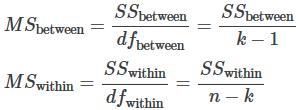
The one-way ANOVA test depends on the fact that MSbetween can be influenced by population differences among means of the several groups. Since MSwithin compares values of each group to its own group mean, the fact that group means might be different does not affect MSwithin.
The null hypothesis says that all groups are samples from populations having the same normal distribution. The alternate hypothesis says that at least two of the sample groups come from populations with different normal distributions. If the null hypothesis (H0) is TRUE,
MSbetween and MSwithin should both estimate the same value.
To be clear, the null hypothesis says that all the group population means are equal. The hypothesis of equal means implies that the populations have the same normal distribution, because it is assumed that the populations are normal and that they have equal variances.
So, all of this brings us to the F-ratio or F-statistic, defined as
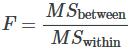
If MSbetween and MSwithin estimate the same value (following the belief that H0 is TRUE), then the F-ratio should be approximately equal to one (1). Mostly, just sampling errors would contribute to variations away from one. As it turns out, MSbetween consists of the population variance plus a variance produced from the differences between the samples. MSwithin is an estimate of the population variance. Since variances are always positive, if the null hypothesis is FALSE, MSbetween will generally be larger than MSwithin. Then the F-ratio will be larger than one. However, if the population effect is small, it is not unlikely that MSwithin will be larger in a given sample.
The foregoing calculations were done with groups of different sizes. If the groups are the same size, the calculations simplify somewhat, and the F-ratio can be written as:
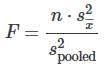
where
- n = the sample size
- dfnumerator = k – 1
- dfdenominator = n – k
- s2pooled = the mean of the sample variances (pooled variance)
- s2/x= the variance of the sample means.
Now that you have had the statistics lecture, you may use the worksheet function F.INV.RT to find the value in the F-distribution that cuts off a given proportion of the area in the upper (right) tail. This should be compared and contrasted with F.INV which finds the value that cuts off a given proportion of the area in the lower (left) tail. Thus, you may use F.INV.RT to find the critical value of F.
The traditional approach has been to obtain a critical F-value early on in an experiment. The researcher would know how many groups would be involved, and would have some knowledge of how many individual observations would be available at the conclusion of the experiment. The variable alpha, the level of significance, would be chosen before any outcome data is available.
As with F.INV, let’s again consider a researcher who was testing four groups consisting of 10 people each, and that alpha was set to a level of 0.05 (5%). Then, an F-value could be looked up in a statistics text or else you could use the following formula to determine the critical F-value:
=F.INV.RT(0.05,3,36).
Important: This function also replaces the older function FINV so that it may provide improved accuracy and whose names better reflect their usage. Although the previous function is still available for backward compatibility, you should consider using this newer function from now on, because the older variant may not be available in future versions of Excel, according to Microsoft.
Further, prior to Excel 2010, you would have to use the following formula instead:
=FINV(0.05,3,36).
These two formulae will return the same value, 2.866. Effectively F.INV(p,…) = F.INV.RT(1-p,…).
Once this has been determined (using either of these Excel functions), the ANOVA test may now be completed , with the calculated F compared to the critical F, and if the former is greater than the latter, the null hypothesis (H0) will be rejected.
In summary, the F.INV.RT function returns the inverse of the F probability distribution. If p = F.DIST.RT(x,...), then F.INV.RT(p,...) = x. The F distribution can be used in an F-test that compares the degree of variability in two data sets.
The F.INV.RT function employs the following syntax to operate:
F.INV.RT(probability,deg_freedom1,deg_freedom2)
The F.INV function has the following arguments:
- probability: this is required and represents the probability associated with the F-cumulative distribution
- deg_freedom1: this is also required and denotes the numerator degrees of freedom
- deg_freedom2: this is again required and represents the denominator degrees of freedom.
It should be further noted that:
- if any argument is non-numeric, F.INV.RT returns the #VALUE! error value
- if probability < 0 or probability >1, F.INV.RT returns the #NUM! error value
- if deg_freedom1 or deg_freedom2 is not an integer, it is truncated
- if either deg_freedom1, deg_freedom2 is strictly less than 1 or deg_freedom2 is greater than or equal to 10^10, F.INV.RT returns the #NUM! error value.
Please see my example below:

We’ll continue our A to Z of Excel Functions soon. Keep checking back – there’s a new blog post every business day.
A full page of the function articles can be found here.