
A to Z of Excel Functions: The CORVARIANCE.P Function
12 February 2018
Welcome back to our regular A to Z of Excel Functions blog. Today we look at the CORVARIANCE.P function.
The CORVARIANCE.P function
I suppose this is how you take the ‘P’ out of covariance… This function measures the linear relationship between random variables representing the entire population. In probability theory and statistics, covariance is a measure of the joint variability of two random variables. If the greater values of one variable mainly correspond with the greater values of the other variable, and the same holds for the lesser values, i.e. the variables tend to show similar behaviour, the covariance is positive. In the opposite case, when the greater values of one variable mainly correspond to the lesser values of the other, i.e. the variables tend to show opposite behaviour, the covariance is negative.

The sign of the covariance therefore shows the tendency in the linear relationship between the variables. The magnitude of the covariance is not easy to interpret because it is not normalised and hence depends on the magnitudes of the variables. The normalised version of the covariance, known as the correlation coefficient, however, shows by its magnitude the strength of the linear relationship.
A distinction must therefore be made between:
- the covariance of two random variables, which is a population parameter that can be seen as a property of the joint probability distribution; and
- the sample covariance, which in addition to serving as a descriptor of the sample, also serves as an estimated value of the population parameter.
This function returns the former (population) covariance, the average of the products of deviations for each data point pair in two data sets. It is used to determine the relationship between two data sets. For example, you can examine whether greater income accompanies greater levels of education.
The CORVARIANCE.P function employs the following syntax to operate:
CORVARIANCE.P(array1, array2)
The CORVARIANCE.P function has the following arguments:
- array1: this is required and represents the first cell range of integers
- array2: this is also required. This is the second cell range of integers.
It should be further noted that:
- this function has replaced an older function (COVAR) and should provide improved accuracy and a name better reflecting its usage
- the arguments must either be numbers or be names, arrays, or references that contain numbers
- if an array or reference argument contains text, logical values, or empty cells, those values are ignored; however, cells with the value zero are included
- if array1 and array2 have a different number of data points, COVARIANCE.P returns the #N/A error value
- if either array1 or array2 is empty, COVARIANCE.P returns the #DIV/0! error value
- the population covariance is given by the formula:
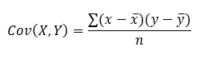
where

are the sample means AVERAGE(array1) and AVERAGE(array2), and n is the population size.
Please see my example below:

We’ll continue our A to Z of Excel Functions soon. Keep checking back – there’s a new blog post every business day.