
A to Z of Excel Functions: The CHISQ.DIST Function
22 May 2017
Welcome back to our regular A to Z of Excel Functions blog. Today we look at the CHISQ.DIST function.
The CHISQ.DIST function
In probability theory and statistics, the chi-squared distribution (also chi-square or χ2-distribution) with k degrees of freedom is the distribution of a sum of the squares of k independent standard normal random variables. It is one of the most widely used probability distributions in inferential statistics, e.g. in hypothesis testing or in construction of confidence intervals.
The chi-squared distribution is used in the common chi-squared tests for goodness of fit of an observed distribution to a proposed theoretical one, the independence of two criteria of classification of qualitative data, and in confidence interval estimation for a population standard deviation of a normal distribution from a sample standard deviation.
If Z1, ..., Zk are independent, standard normal random variables, then the sum of their squares
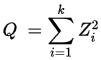
is distributed according to the chi-squared distribution with k degrees of freedom. This is usually denoted as
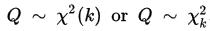
Thus, the chi-squared distribution has one parameter: k — a positive integer that specifies the number of degrees of freedom.
As aforementioned, the chi-squared distribution is used primarily in hypothesis testing. Unlike more widely known distributions such as the normal distribution and the exponential distribution, the chi-squared distribution is rarely used to model natural phenomena. It arises in the following hypothesis tests, among others.
The primary reason that the chi-squared distribution is used extensively in hypothesis testing is its relationship to the normal distribution. Many hypothesis tests use a test statistic, such as the t statistic in a t-test. For these hypothesis tests, as the sample size, n, increases, the sampling distribution of the test statistic approaches the normal distribution (Central Limit Theorem). Since the test statistic (such as t) is asymptotically normally distributed, provided the sample size is sufficiently large, the distribution used for hypothesis testing may be approximated by a normal distribution. Testing hypotheses using a normal distribution is well understood and relatively easy. The simplest chi-squared distribution is the square of a standard normal distribution. So wherever a normal distribution could be used for a hypothesis test, a chi-squared distribution could be used.
A chi-squared distribution constructed by squaring a single standard normal distribution is said to have 1 degree of freedom, etc.
The chi-squared distribution is commonly used to study variation in the percentage of something across samples, such as the fraction of the day people spend reading these articles about obscure Excel functions. This should not be confused with the CHIDIST function which returns the right-tailed probability of the chi-squared distribution.
The CHISQ.DIST function employs the following syntax to operate:
CHISQ.DIST(x, deg_freedom, cumulative)
The CHISQ.DIST function has the following arguments:
- x: this is required and represents the value at which you want to evaluate the distribution
- deg_freedom: this is also required. This denotes the number of degrees of freedom
- cumulative: this is another mandatory argument. This is a logical value that determines the form of the function. If cumulative is TRUE, CHISQ.DIST returns the cumulative distribution function; if cumulative is FALSE, it returns the probability density function.
It should be further noted that:
- if any argument is nonnumeric, CHISQ.DIST returns the #VALUE! error value
- if x is negative, CHISQ.DIST returns the #NUM! error value
- if deg_freedom is not an integer, it is truncated
- if deg_freedom < 1 or deg_freedom > 10^10, CHISQ.DIST returns the #NUM! error value.
Please see my example below:

We’ll continue our A to Z of Excel Functions soon. Keep checking back – there’s a new blog post every other business day.